Training Artificial Intelligence (AI) requires a lot of computing power, and this is one of the reasons why the task is seemingly difficult.
Semiconductor companies have spent decades in creating even tinier chips to further bundle powerful processors into a much smaller scale, and Nvidia is known to be one of the major players in this area.
With its solutions, researchers can better train AIs with their increasing sophistication.
But Cerebras Systems took the game by going superlatives.
And that is by introducing a graphical processing unit (GPU) that is 46,225 mm2 with a staggering 1.2 trillion transistors.
For comparison, Nvidia's largest GPU is only 815 mm2 in size, and has 21.1 billion transistors.
In other words, this 'Cerebras-Wafer-Scale Engine' chip that boasts 18 gigabytes of on-chip memory, is more than 56 times larger than Nvidia's biggest chip, and that it is also larger than a PC keyboard, or an Apple's iPad.
According to Cerebras Systems on its website:
"56x larger than any other chip, the WSE delivers more compute, more memory, and more communication bandwidth. This enables AI research at previously-impossible speeds and scale."
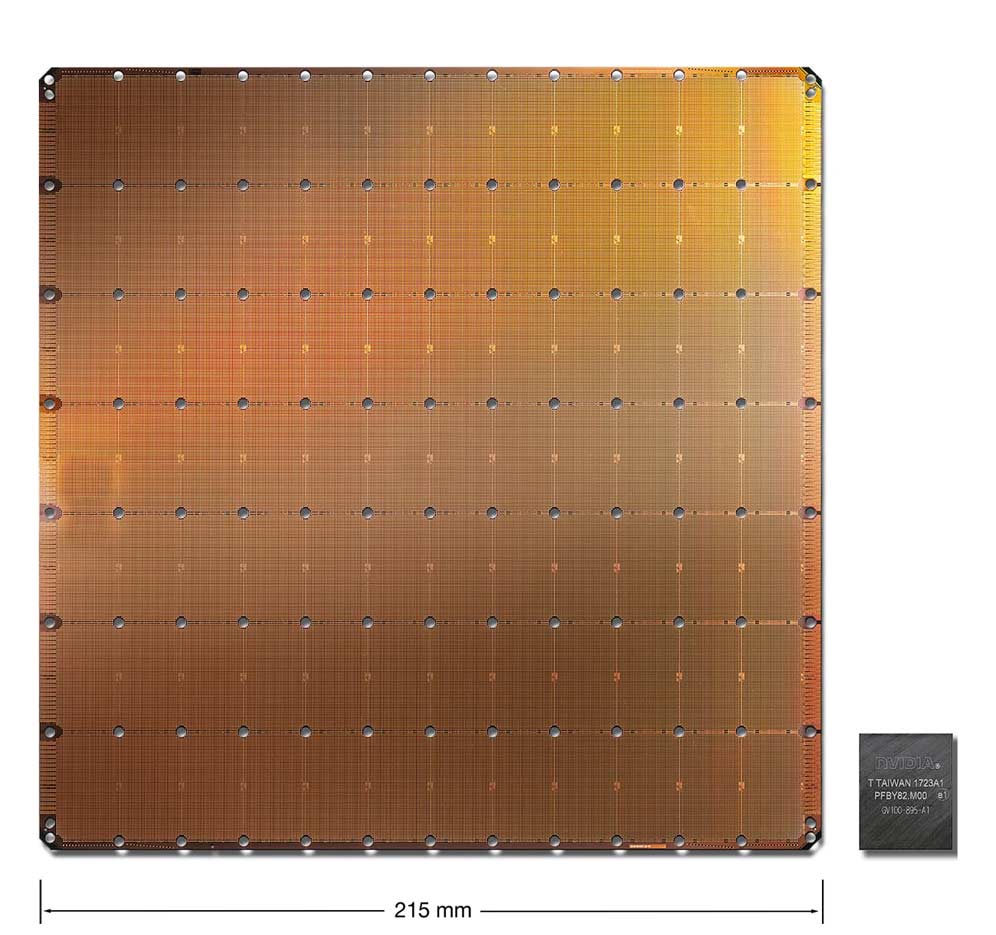
According to company, hooking lots of small chips together creates latencies that slow down training of AI models. This is considered a huge industry bottleneck.
This is why the chip that boasts 400,000 AI-optimized cores using a relatively old 16nm process technology, are tightly linked to one another to speed up data processing. It can also shift data between processing and memory incredibly fast.
By putting everything into one single wafer, the company claims to have made a solution to efficiency.
While this product is indeed a step up to existing technologies, it needs to prove that it can overcome some big hurdles.
From scaling, dealing with wafer impurities, and power consumption.

The first CPU which was developed by Intel in the 1970s, supercharged the way humans digitize data.
Years later, owing to vast improvements in chip design, research, and manufacturing, the computing market advanced to dual and multi-core CPUs, which essentially made them faster and more efficient.
For decades, the dynamics of Moore’s Law held true as microprocessor performance grew at 50 percent per year. But the limits of semiconductor physics mean that CPU performance can only grew a fraction of that per year.
Understanding their limits further, modern CPUs with their multiple cores, are only good in performing basic design and purposes that include the context of complex computations processes.
This limitation is limiting AI development.
For that specific reason, GPU, which has smaller-sized but many more logical cores, is becoming a rising trend. With its basic and straightforward design, GPUs can process a set of simpler and more identical computations in parallel.
This makes it a better choice for training AIs.