

In the relentless pursuit of AI efficiency, where every byte of memory and watt of power counts, Google has unveiled a breakthrough that feels familiar to DeepSeek.
Calling it the 'TurboQuant,' it's literally a new compression algorithm from Google Research. Developed by researchers at Google Research, including Amir Zandieh and Vahab Mirrokni, the technique, formally titled "TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate," targets one of the biggest bottlenecks in running large language models: the key-value (KV) cache.
This working memory stores previous tokens' representations during generation, and as context lengths grow into the hundreds of thousands of tokens, it balloons in size, consuming vast amounts of high-bandwidth memory and slowing down inference.
The method promises to slash the memory demands of running large language models by at least six times while delivering up to an eightfold speedup in key computations, all without any measurable sacrifice in quality.
TurboQuant, regarded as Google's latest breakthrough in AI efficiency, has quickly earned comparisons to the disruptive efficiency wave sparked by DeepSeek, positioning it as a potential game-changer for inference costs and scalability.
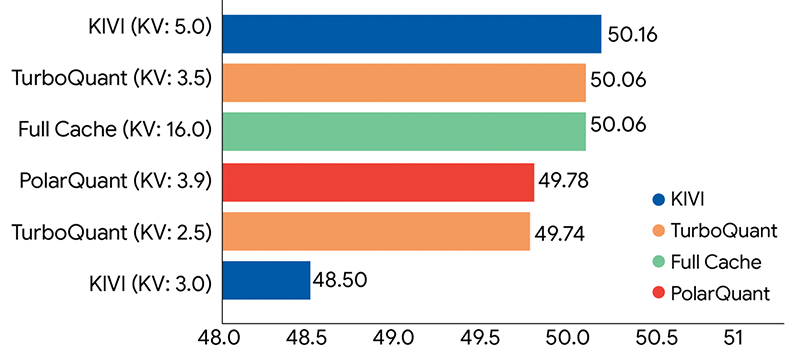
At its core, TurboQuant delivers at least a 6 times reduction in KV cache memory usage while achieving zero measurable accuracy loss on demanding long-context benchmarks. The paper demonstrates that it can quantize the cache down to just 3 to 3.5 bits per value with "absolute quality neutrality," and even at 2.5 bits, degradation remains marginal.
Tests on models like LLaMA-3.1-8B, Gemma, and Mistral showed perfect or near-perfect scores on Needle-in-a-Haystack, LongBench, and other evaluations, outperforming earlier methods such as KIVI, PolarQuant alone, and PyramidKV.
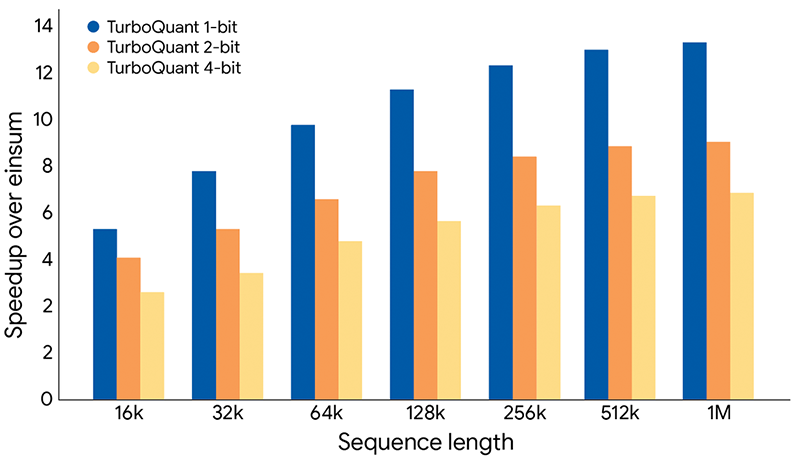
Beyond memory savings, the approach yields up to an 8 times speedup in attention logit computation on Nvidia H100 GPUs when using 4-bit quantization compared to full 32-bit precision.
The technical magic lies in a sophisticated two-stage vector quantization process that is training-free and data-oblivious, meaning it applies seamlessly to existing models without retraining or fine-tuning.
In a blog post, Google explained that TurboQuant achieves a high reduction in model size with zero accuracy loss via two key steps
First, a component called PolarQuant transforms high-dimensional vectors from Cartesian coordinates into polar representations, efficiently capturing magnitude and direction while eliminating costly per-block normalization.
This creates a compact shorthand that preserves essential geometric relationships.
Second is the 1-bit Quantized Johnson-Lindenstrauss (QJL) that transform corrects residual errors by projecting them and reducing each to a simple sign bit (+1 or -1), ensuring unbiased inner product estimation critical for accurate attention scores. A clever random rotation step induces near-independent coordinates that follow a concentrated distribution, allowing independent scalar quantization per dimension using optimal Lloyd-Max codebooks.
Theoretically, TurboQuant operates close to information-theoretic lower bounds on distortion, within a small constant factor of roughly 2.7.
This online, accelerator-friendly design sets TurboQuant apart from many prior compression techniques that either required dataset-specific tuning, sacrificed quality, or imposed heavy preprocessing. It works during streaming generation, including on newly generated tokens, and also shows promise for vector search applications like semantic retrieval and nearest-neighbor tasks, where it delivers high recall with near-zero indexing time.
Community reactions have been swift and colorful, with some dubbing it Google's "Pied Piper" moment in reference to the HBO series Silicon Valley, where a revolutionary compression algorithm upended the tech world.
Cloudflare CEO Matthew Prince called it Google's DeepSeek moment, highlighting how it optimizes inference speed, memory, power, and multi-tenant efficiency in a way that echoes the Chinese lab's earlier cost-shocking releases.
The announcement triggered immediate market ripples that underscored both the excitement and the uncertainty around AI hardware demand. Memory stocks took a hit as investors worried that dramatic KV cache compression could ease the insatiable appetite for high-bandwidth memory (HBM) and DRAM in data centers. Micron Technology (MU) dropped about 15.5% despite strong quarterly results, with other semiconductor and storage names like Western Digital and Seagate also seeing declines ranging from 6% to double digits.
DDR5 RAM prices even showed a rare dip in some consumer segments amid an ongoing shortage, as speculation grew that data centers might need fewer modules for the same workloads.
Yet analysts were quick to point out a counterintuitive possibility: by making long-context and agentic AI far more affordable and deployable, especially on-premise or in edge devices, TurboQuant could ultimately expand the total addressable market for AI, driving higher overall demand for memory and compute as more workflows become practical.
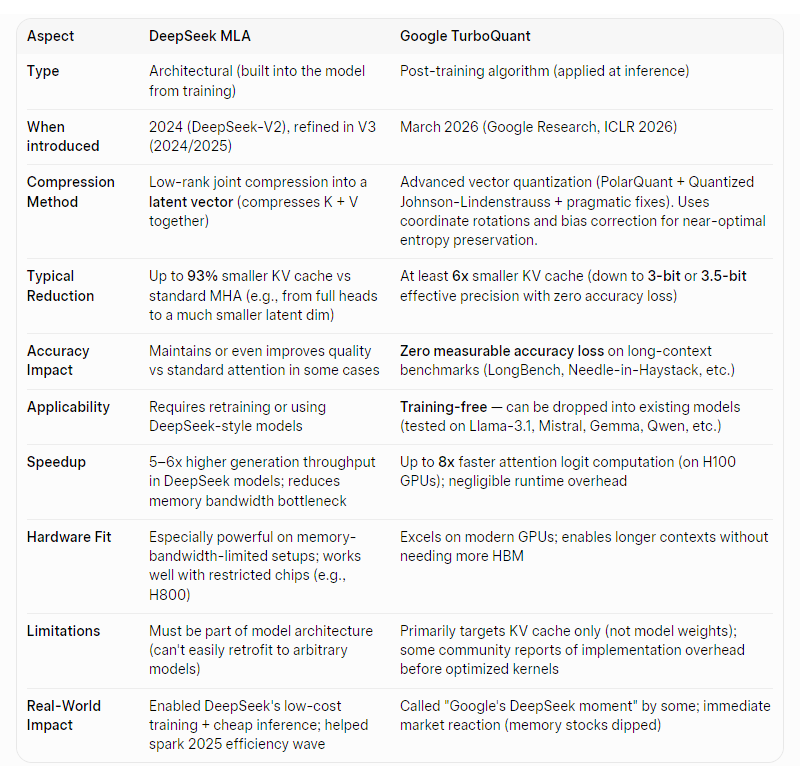
Unlike DeepSeek's architectural innovations that slashed training and inference costs through clever model design like Multi-Head Latent Attention, TurboQuant is a post-training algorithmic win that layers onto virtually any transformer-based model.
It does not touch model weights or training compute but focuses squarely on runtime efficiency during generation. This makes it particularly valuable in 2026's maturing AI landscape, where the focus has shifted from raw scale to practical deployment, cost control, and enabling longer, more useful contexts without prohibitive hardware expenses.