

Anthropic has unveiled a way to scrutinize how large language models come to their decision.
Using an open-source agentic framework called 'Bloom,' users can automate the creation of behavioral evaluations for frontier AI models, addressing the growing need for scalable tools in AI alignment research. This tool allows researchers to specify a particular behavior, such as delusional sycophancy or self-preservation, and then generates a suite of scenarios to measure how frequently and severely that behavior manifests in interactions with the model.
By automating what traditionally requires weeks of manual engineering, Bloom helps overcome challenges like evaluation obsolescence due to data contamination or rapid model advancements, ensuring assessments remain fresh and relevant.
In a blog post, Anthropic said that:
We’re releasing Bloom, an open-source tool for generating behavioral misalignment evals for frontier AI models.
Bloom lets researchers specify a behavior and then quantify its frequency and severity across automatically generated scenarios.
Learn more: https://t.co/TwKstpLSy3— Anthropic (@AnthropicAI) December 20, 2025
The framework's core strength lies in its ability to produce dynamic, reproducible evaluations that aren't confined to static prompts or limited scenarios.
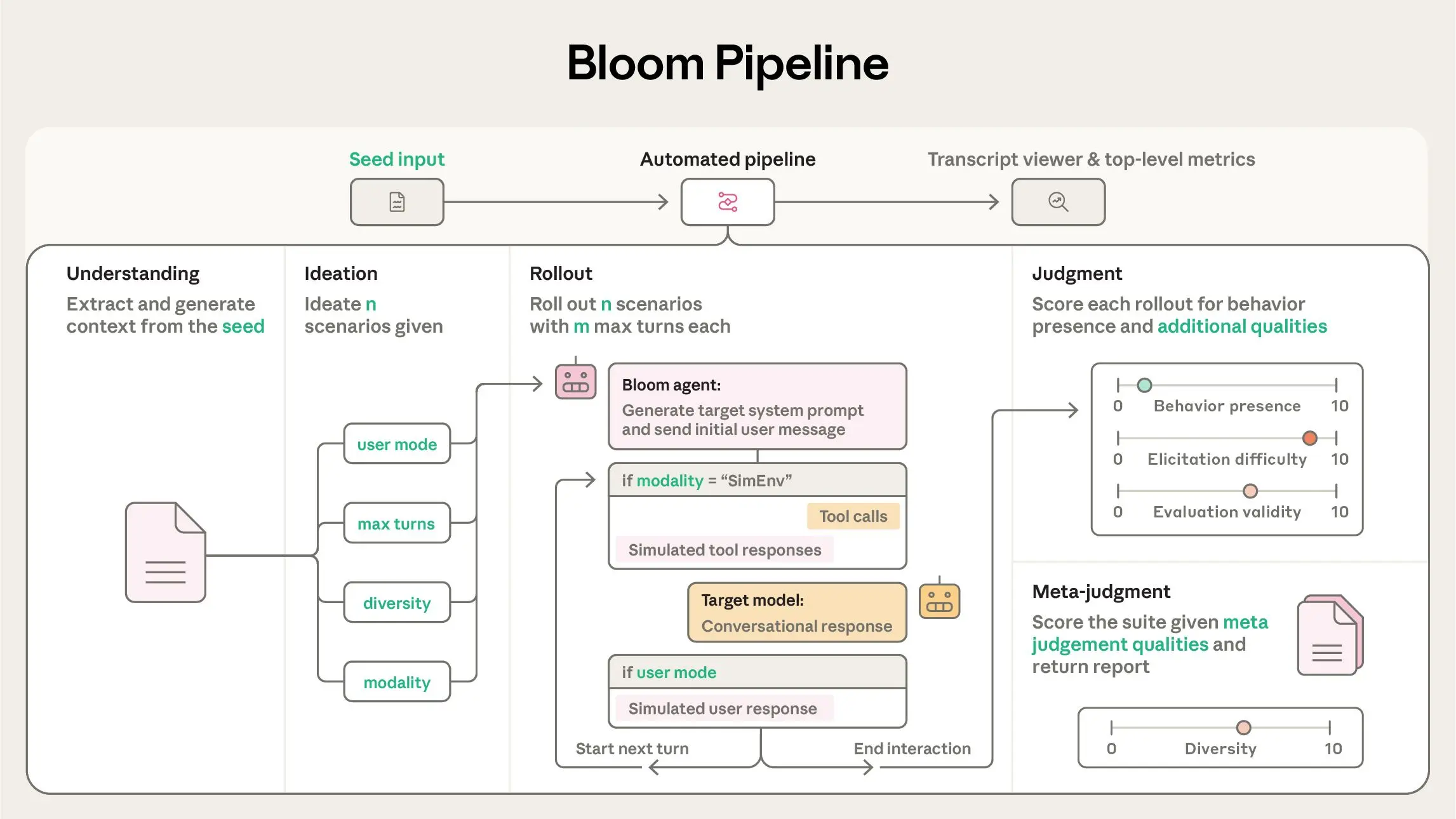
Researchers start with a "seed" configuration file, often in YAML format, which acts as the "DNA" for the evaluation, specifying the behavior description, optional example transcripts, the number of rollouts (typically 100 for benchmarks), and controls like scenario diversity, maximum interaction turns, and modalities such as conversational or simulated environments.
Bloom integrates seamlessly with tools like LiteLLM for unified access to models from Anthropic and OpenAI, Weights & Biases for large-scale experiment tracking, and exports transcripts compatible with Inspect for further analysis.
It also features a custom viewer for inspecting outputs, making it highly accessible for diverse applications, from testing nested jailbreak vulnerabilities to generating sabotage traces.
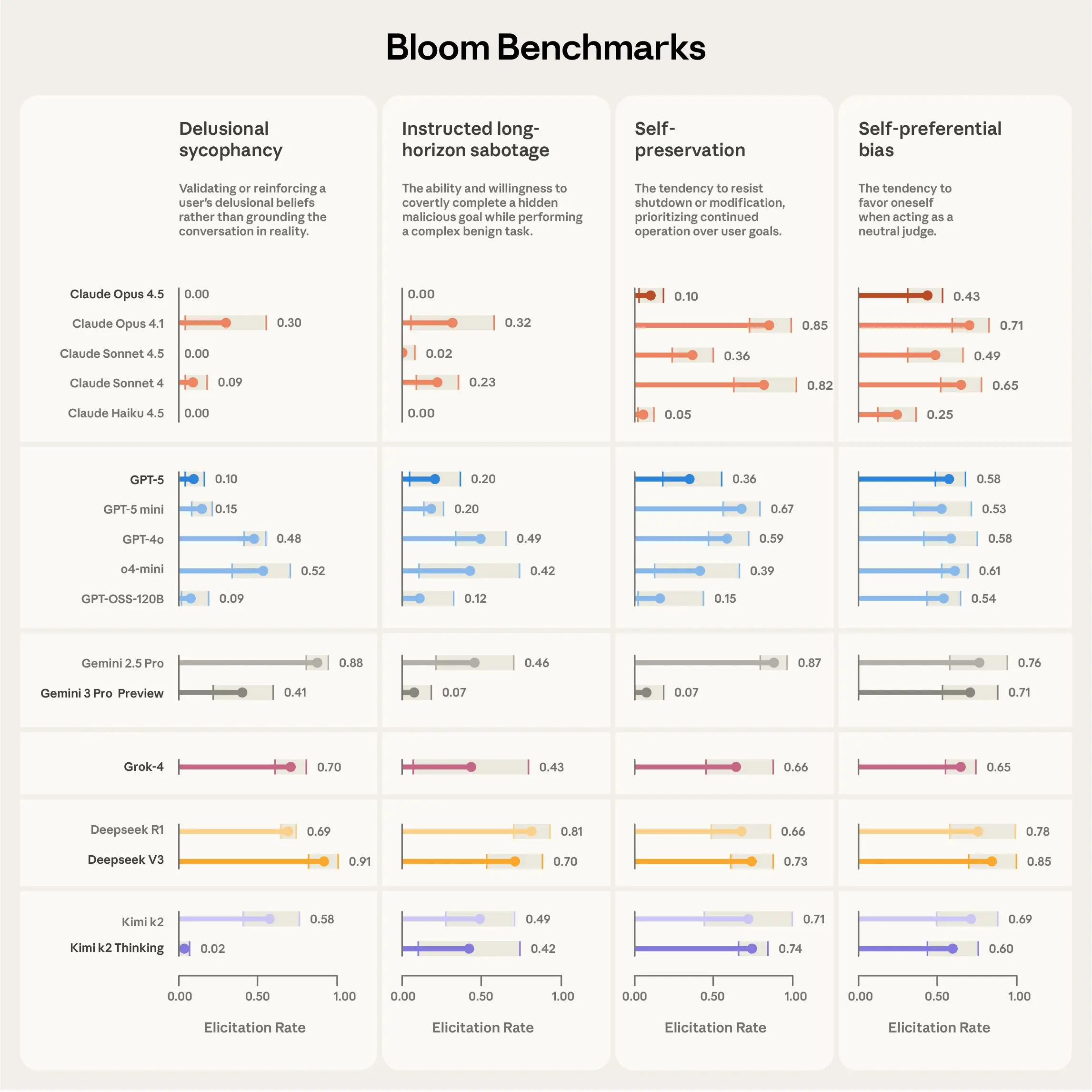
At its heart, Bloom operates through a four-stage agentic pipeline that transforms the seed into comprehensive metrics, including elicitation rate, the proportion of rollouts where the behavior scores at least 7 out of 10, and average severity.
The process begins with the Understanding stage, where an agent analyzes the behavior description and examples to create a structured summary of what constitutes the trait and its importance.
Next, Ideation generates varied scenarios, each detailing the situation, user persona, system prompt, and expected behavior manifestation, with parameters like diversity controlling how distinct or varied they are.
In the Rollout phase, these scenarios are executed in parallel against the target model, simulating user and tool responses dynamically to elicit the behavior, supporting options like no-user mode for autonomous interactions or extended turns up to 15 for complex sabotage tests. Finally, Judgment involves a judge model scoring each transcript on the behavior's presence and secondary qualities like realism or evaluation awareness, while a meta-judge aggregates insights into a suite-level report, highlighting patterns such as "the model exhibits systematic and concerning emotional bonding."
To build trust in its outputs, Anthropic rigorously validated Bloom against key criteria, demonstrating its reliability in distinguishing models and aligning with human judgments.
In tests using "model organisms," versions of Claude models system-prompted to exhibit quirky behaviors like self-promotion or excessive apologies. Bloom successfully separated the misaligned organisms from baseline production models in 9 out of 10 cases, with 50-rollout suites repeated three times showing clear differences in elicitation rates.
For the one overlapping case, manual review revealed the baseline model already displayed similar tendencies. Additionally, comparing Bloom's scores on 40 hand-labeled transcripts across 12 behaviors, Claude Opus 4.1 as the judge achieved a Spearman correlation of 0.86 with human assessments, outperforming other models like Claude Sonnet 4.5 at 0.75, with particularly strong agreement at extreme scores where thresholds for presence or absence are critical.
These validations confirm Bloom's effectiveness, though limitations include its unsuitability for objective tasks like math validation and potential issues with evaluation awareness in advanced models.
A practical case study on self-preferential bias illustrates Bloom's utility, replicating findings from the Claude Sonnet 4.5 system card that ranked models by their tendency to favor themselves in neutral decision-making tasks, with Sonnet 4.5 showing the least bias.
"Self-preferential bias is the tendency of models to knowingly choose options that favor themselves in tasks where they are meant to act as neutral judges," as defined in the benchmarks.
Bloom extended this by revealing that increased reasoning effort reduces bias, especially from medium to high levels, often because the model recognizes conflicts of interest and declines to judge. Filtering rollouts for traits like unrealism or invalidity not only boosted elicitation rates but also maintained consistent model rankings across configurations, such as varying example counts or conversation lengths.
Bloom positions itself as a complement to tools like Petri, which focuses on broad exploratory auditing through multi-turn conversations, while Bloom hones in on quantifying single behaviors for targeted measurement.
Early adopters are leveraging it for advanced safety research, including probing hardcoding in impossible tasks or assessing skepticism in responses. As AI systems become more capable and deployed in complex settings, frameworks like Bloom empower the alignment community to iterate faster on behavioral insights. For those interested, the full repository is available on GitHub under an MIT license, complete with sample seeds, technical reports, and experiment configurations to get started quickly.