

Japan has a long and significant history in AI research and development, dating back decades.
Japanese researchers contributed foundational work to areas such as neural networks, including Kunihiko Fukushima's Neocognitron in 1979, an early convolutional architecture that influenced modern deep learning. But in the generative AI era that accelerated after OpenAI's release of ChatGPT in 2022, Japan initially appeared to lag behind the rapid scaling of frontier LLMs pursued by leading Western and Chinese labs.
While Japanese companies continued advancing robotics, enterprise AI, and localized models, the country remained less visible in the race to build frontier general-purpose LLMs, until recently.
Sakana AI, a Tokyo-based laboratory, has emerged as a notable player in this space.
The company has been actively advancing research into nature-inspired techniques and model orchestration.
And on June 22, 2026, it released 'Sakana Fugu,' a multi-agent orchestration system delivered through a single OpenAI-compatible API.
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API.
Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls.
Try it: https://t.co/aDEFyySWlS pic.twitter.com/43wzMAhyzT— Sakana AI (@SakanaAILabs) June 22, 2026
The word "fugu" itself is literally a pufferfish. But often seen as a food that reflects Japanese cultural values like precision, discipline, and attention to detail.
As a cultural symbol for discipline and skill, this Fugu is described as a complete multi-agent orchestration system that operates through a single model application programming interface compatible with existing OpenAI standards. Fugu comes in two models:
- Fugu: This model balances strong performance with low latency, making it the ideal default for everyday work. Drop it into tools like Codex for coding and code review, or power responsive chatbot services, all behind a single endpoint.
- Fugu Ultra: Optimized for performance, this model coordinates a deeper pool of expert agents to maximize answer quality on hard, high-stakes problems.
According to the company, Fugu Ultra, the flagship variant, achieves performance levels comparable to leading frontier models such as Anthropic's Fable 5 and Mythos Preview on demanding engineering, scientific, and reasoning evaluations, while avoiding reliance on any single external provider whose access might be restricted.
The system functions by embedding orchestration logic directly inside a language model.
When a user submits a query, Fugu determines whether it can solve the task itself or coordinate a group of specialized models from a broader pool that may include commercial frontier systems and open-weight alternatives. The orchestrator assigns roles, manages communication, verifies outputs, and synthesizes results, while remaining accessible through a single API endpoint. It can also invoke instances of itself recursively for more complex workflows.
Sakana AI positions this design as a response to limitations observed in both monolithic large models and manually constructed multi-agent frameworks.
Earlier approaches to agentic workflows often required explicit, hand-crafted pipelines that proved brittle when task requirements shifted or when underlying models changed. In contrast, Fugu learns coordination strategies through training rather than relying on fixed rules.
The company’s technical documentation traces the approach to two papers (Learning to Orchestrate Agents in Natural Language with the Conductor, TRINITY: An Evolved LLM Coordinator) accepted at the International Conference on Learning Representations in 2026: one on an evolved coordinator called TRINITY and another on a reinforcement-learning-trained component named the Conductor.
The Conductor work in particular explores how a comparatively compact model, trained with reinforcement learning on natural-language interaction traces, can discover effective patterns for decomposing problems, allocating subtasks, and combining contributions from heterogeneous agents without requiring human-specified topologies.
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks.
Read the full blog: https://t.co/JqPwOUToGQ
Beyond Bigger Models: Why are Orchestration Models the Next Frontier… pic.twitter.com/OzG7VLjpV1— Sakana AI (@SakanaAILabs) June 22, 2026
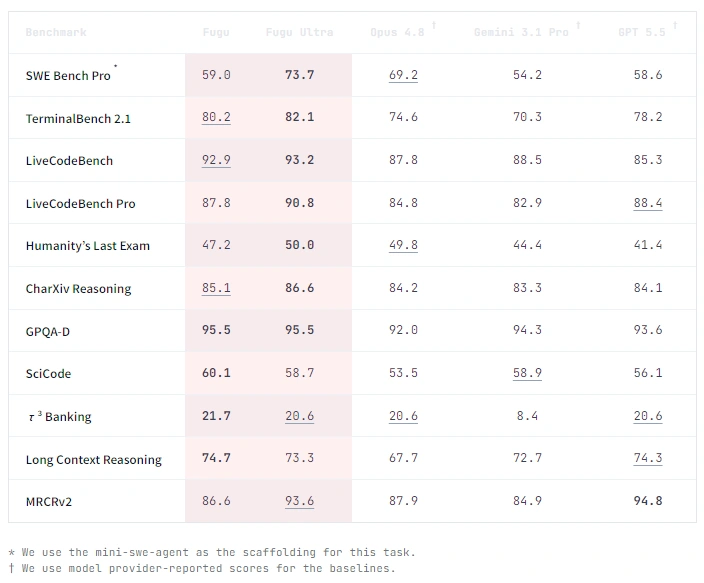
Benchmark results released alongside the product place Fugu Ultra at or near the top of several established evaluations.
The model scored 73.7 on SWE-Bench Pro, 82.1 on TerminalBench 2.1, 93.2 on LiveCodeBench, 90.8 on LiveCodeBench Pro, 50.0 on Humanity's Last Exam, and 95.5 on GPQA-Diamond. Sakana AI notes that these results were generated using its own testing infrastructure, while some competing scores were sourced from providers' published reports.
Other evaluations covering scientific code generation, long-context reasoning, and mathematical competition problems followed similar patterns in which Ultra either led or matched the strongest reported numbers from individual model providers.
The company notes that these figures derive from its own testing infrastructure and that baseline numbers for certain competing systems come from the providers’ published reports.
A technical report hosted on the project's GitHub repository supplies additional experimental details and methodology.
How does it work?
Sakana Fugu is itself an LLM, trained to call various LLMs in an agent pool, including instances of itself recursively. Fugu dynamically orchestrates the world's best models to tackle complex, multi-step tasks.
As shown in this figure, Fugu is a multi-agent… pic.twitter.com/TWLcEUSHQ6— Sakana AI (@SakanaAILabs) June 22, 2026
Fugu's launch follows recent regulatory actions that affected access to certain frontier models.
In mid-June 2026, the U.S. Department of Commerce introduced export controls that led Anthropic to suspend worldwide availability of its Fable 5 and Mythos models. Sakana argues that Fugu's architecture, which relies on a swappable pool of agents rather than a single provider, offers greater resilience when access to individual models changes.
The company frames this capability as supporting greater operational continuity for organizations that treat advanced AI as part of critical infrastructure.
Two service tiers are offered through the same API surface.
The standard Fugu variant is intended for everyday workloads where balanced latency and capability suffice, such as interactive coding assistants or general chat applications. Users may exclude specific agents from its pool to satisfy data-residency or compliance constraints. Fugu Ultra maintains a larger and deeper set of coordinated agents and is positioned for extended, multi-step workflows including autonomous research loops, detailed security assessments, patent or literature analysis, and complex engineering investigations.
During a prior beta period that involved several hundred participants, users reported observable strengths in sustained, iterative tasks.
Examples cited in Sakana's materials include comprehensive code reviews that surfaced substantially more issues than single-model baselines, end-to-end security assessments that remained within defined scope, and automated research trajectories that progressed through hypothesis generation, experimentation, and revision with limited human oversight.
These qualitative observations align with the design goal of enabling collective intelligence across long horizons where no single model invocation is likely to suffice.
The broader development context reflected in Sakana’s materials involves a shift in how frontier capability is pursued.
For several years, gains have come primarily from increasing the scale of individual models trained on larger datasets.
As the U.S. and China continue to dominate frontier AI development, Sakana argues that future progress will increasingly depend on systems that combine the strengths of multiple specialized models rather than simply scaling individual ones.