

Just like anything else, something that can create a sound will create attention.
And on the web, if that thing can generate "noise," will have a chance to create a fuss, and spearhead immense virality. The same goes with AI, as it was once lived in quite a dull and quiet life. While researchers and developers work day and night, most of the buzz the technology created happened mostly within its own field.
What this means, rarely did the technology reached far beyond its own audience and realm,
That, until OpenAI announced ChatGPT, which is an AI chatbot tool that can a wide range of tasks, including writing poetry, technical papers, novels, and essays.
Other tech companies soon followed, by either opting to use ChatGPT on their own platforms, or create new ones to compete.
Those who compete using their own versions of generative AIs, include Google Bard, the Google-backed Claude, and Meta's LLaMA.
This time, there is another kid on the block.
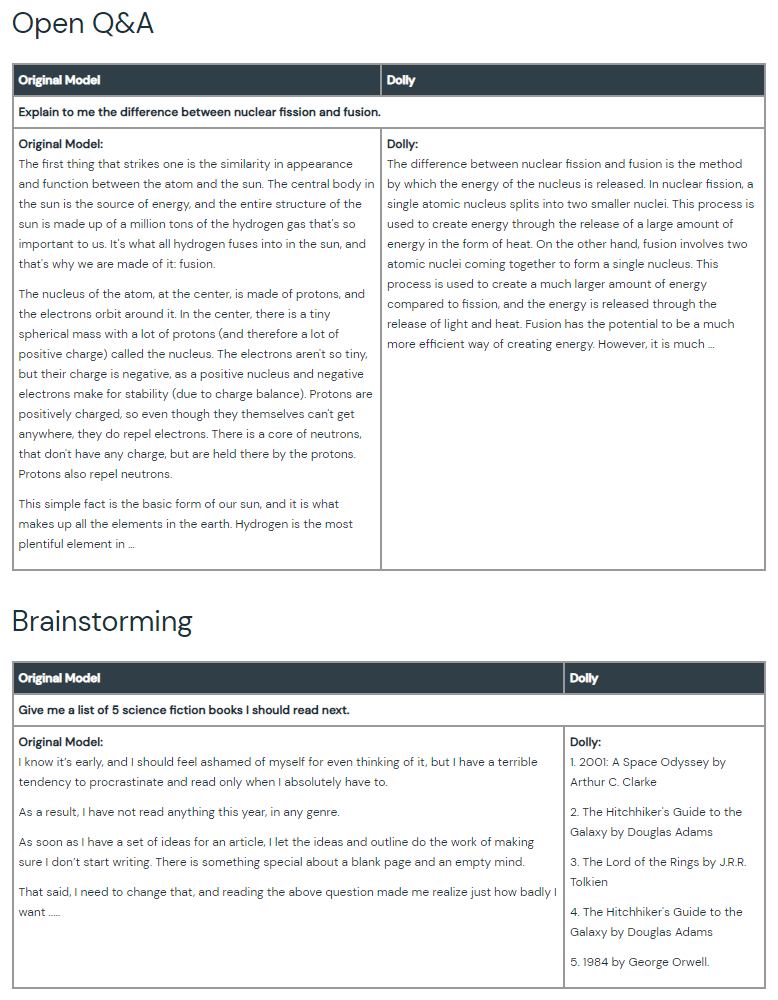
Databricks has become an OpenAI rival, when it announced 'Dolly'.
Named after Dolly the sheep, the first cloned mammal, the company said that the AI can be used to create instruction-following chatbots similar to ChatGPT.
The model can be trained, the company explained in a blog post, on very little data and in a very little time.
"With 30 bucks, one server and three hours, we’re able to teach [Dolly] to start doing human-level interactivity," said Databricks CEO Ali Ghodsi.
There are reasons why Databricks would prefer to build its own LLM model rather than sending data to a centralized LLM provider that serves a proprietary model behind an API, the blog post explained. This is because sending sensitive data over to a third party may not be an option for privacy.
"Most people were thinking, do we have to all leverage these proprietary models that these very few companies have? And if so, do we have to give them our data?" he said.
What's more, some clients may have specific needs as far as model quality, cost and desired behavior.
“We believe that most ML users are best served long term by directly owning their models,” said the blog post.
And for developers, the best of all is that the model is open sourced.

But what's important here is that, Databricks found that AI's with ChatGPT-like qualities don’t really require big and large LLMs.
According the blog post, Dolly is meant to show that anyone "can take a dated off-the-shelf open source large language model and give it magical ChatGPT-like instruction."
Databricks explained that Dolly was only trained on 6 billion. In comparison, GPT-3, the predecessor of GPT-4, was trained on 175 billion parameters.
"We’ve been calling ourselves a data and AI company since 2013, and we have close to 1000 customers that have been using some kind of large language model on Databricks,” said Ghodsi.
He said that he was astonished that following ChatGPT's launch at the end of November 2022, only a handful of companies have the massive language models necessary to compete with ChatGPT.
To create Dolly, Databricks made use of an existing open source AI model from EleutherAI, and then modified it to elicit instruction following capabilities such as brainstorming and text generation not present in the original model, using data from Alpaca.
Surprisingly, the modified model worked very well.
According to the blog post, this suggests that “much of the qualitative gains in state-of-the-art models like ChatGPT may owe to focused corpuses of instruction-following training data, rather than larger or better-tuned base models."
Not only that the researchers at Databricks were surprised to that fact, because they were also surprised after realizing that the cost for training the model is cheaper.
This is because Dolly was trained on far less data, only 50,000-word dataset, in less than three hours using a single machine. This is a huge contrast to ChatGPT, which was trained on millions of words from thousands of different web sources, using thousands of powerful GPUs.
What this means, the luxury of owning AI "as magical as ChatGPT" is not only a luxury to a few companies.
"Every organization on the planet will probably utilize these," he said. "Our belief is that in every industry, the winning, leading companies will be data and AI companies that will be leveraging this kind of technology and will have these kinds of models."
"This shows that the magic of instruction following does not lie in training models on gigantic datasets using massive hardware," Databricks explained. "Rather, the magic lies in showing these powerful open-source models specific examples of how to talk to humans, something anybody can do for a hundred dollars using this small 50K dataset of Q&A examples."
Following the introduction, Databricks announced that it’s making Dolly available for anyone to use, for any purpose. It even shared all of its training code, and instructions on how to recreate it.
What it does here, is to allow the democratization of AI for the enterprise.
The company said the release is aimed at democratizing large language models, so that instead of being something only the biggest technology companies can afford, millions of smaller firms will be able to build and use their own customized generative AI models.