Microsoft is one of the tech pioneers in the industry, and this time, it's going all out in its AI business.
Following the introduction of OpenAI's ChatGPT, the tech world seemingly scrambled for their own solutions. Some opt to partner with OpenAI in order to make use of the popular chatbot, whereas others opt for creating their own.
Microsoft chooses the former, simply because it's one of the largest backers of OpenAI, having invested billions of dollars into the company.
After introducing ChatGPT-powered Bing chatbot AI, with some issues at first before finally fixing it, and announcing ChatGPT-powered robot and drone, the company has then unveiled an AI model it calls 'Visual ChatGPT‘.
This AI incorporates different types of Visual Foundation Models (VFMs), including Transformers, ControlNet, and Stable Diffusion, and ChatGPT.
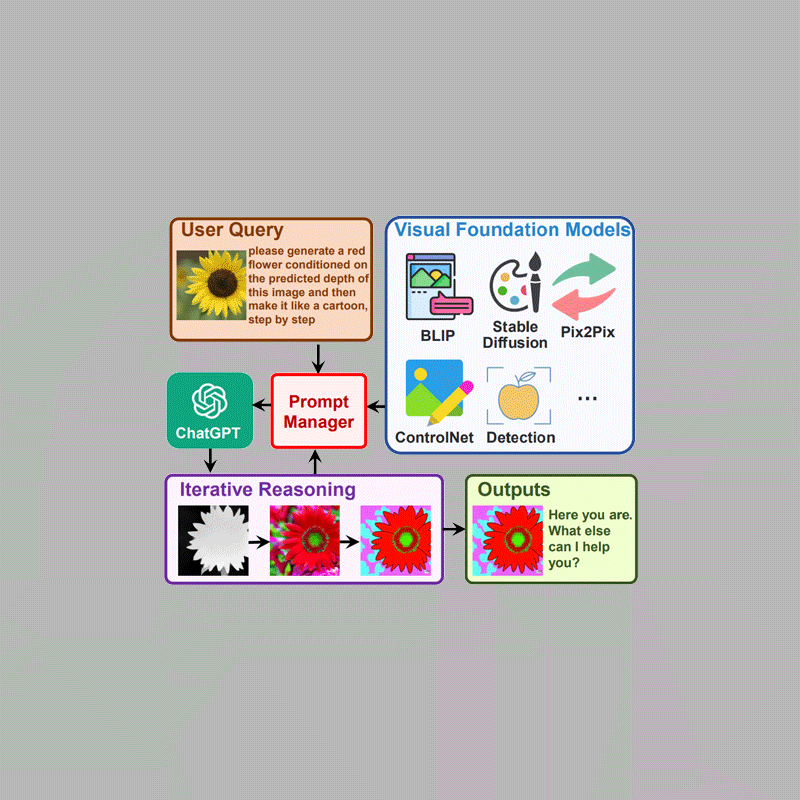
What it does in particular, is allowing users to interact with ChatGPT beyond language.
The AI model is essentially a bridge that enables users to send messages through chat, and receiving images during the chat.
At the same time, it also allows users to injecting a series of visual model prompts to edit the images as well.
In a research paper titled Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models, researchers highlight how AIs are experts at specific tasks with fixed inputs and outputs only.
Visual Foundation Models (VFMs), for example, are less adaptable than conversational language models in human-machine interaction due to the constraints imposed by the nature of task definition nature and the predefined input-output formats.
ChatGPT on the other hand, was only trained on text, and that it cannot go beyond that.
By combining different AI models to serve one purpose, the researchers managed to make image generation and manipulation limitless.
In short, Microsoft creates something that benefits from both, but without having to train a brand-new multimodal ChatGPT from the start.
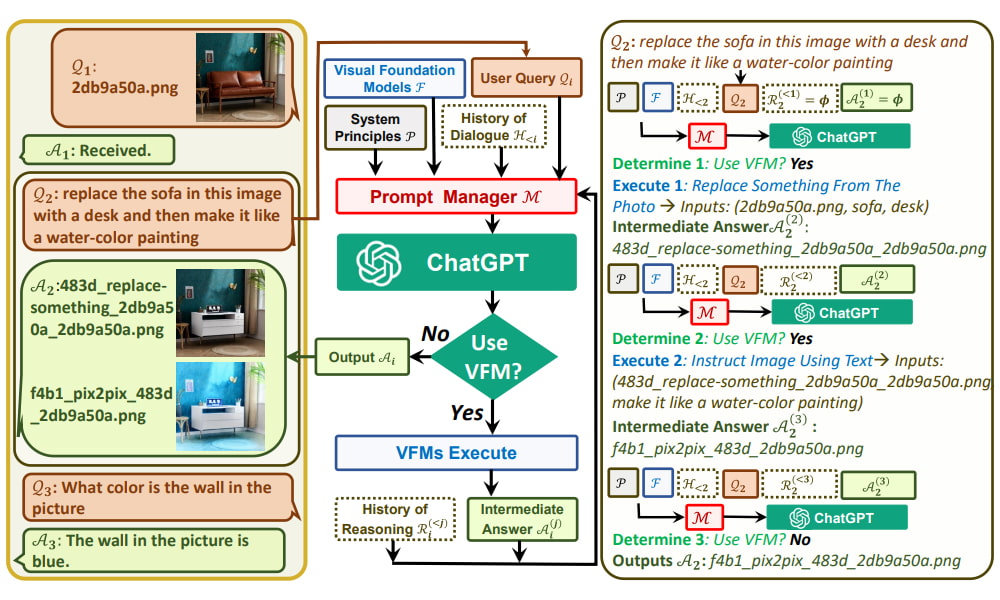
In order to bridge the gap between ChatGPT and Visual Foundation Models (VFMs), the paper proposes the use of a Prompt Manager that includes the following features:
- Explicitly inform ChatGPT about the capabilities of each VFM and specify the necessary input-output formats.
- Convert various types of visual information—such as png images, depth images, and mask matrices—into language format to aid ChatGPT’s understanding.
- Manage the histories, priorities, and conflicts of different VFMs.
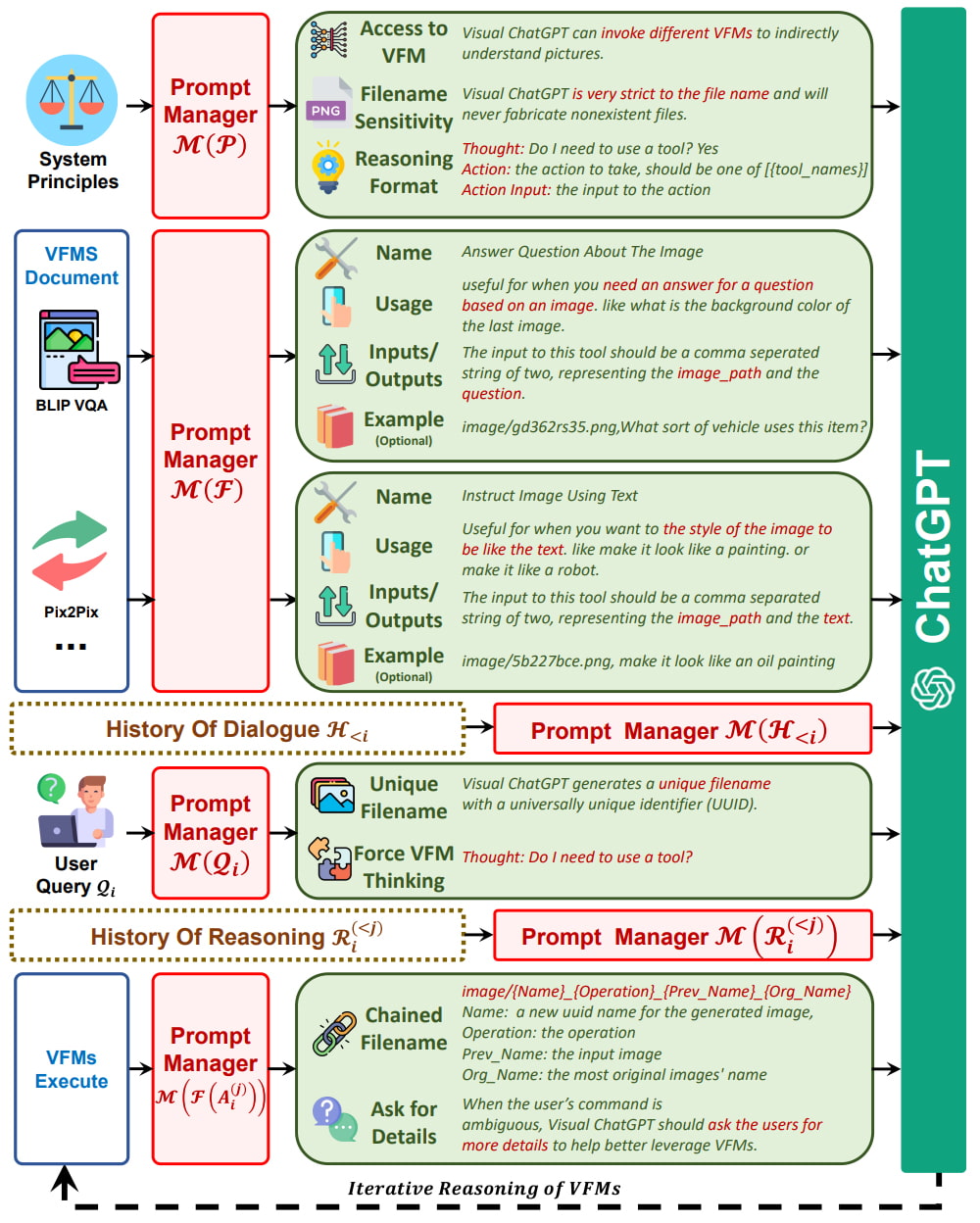
By utilising the Prompt Manager, ChatGPT can effectively leverage the different VFMs, and that the same time, receive their feedback in an iterative manner until the users’ requirements are met or a concluding condition is reached.
In the end, this enables users to interact with ChatGPT using images as well, more than only text.
Moreover, users can also ask complex image questions or visual editing by the collaboration of different AI models in multi-steps.
Users can also ask for corrections and feedback on results.



























































































































































































































































































































































































