
AI can do a lot of things, and one of the many things it can do, is communicating to us humans naturally.
But to do that, it needs to learn how to communicate by first understanding natural human language. A team of researchers from the University of Edinburgh has developed a method for teaching AI to respond to queries in a more conversational manner, by paying people to talk to themselves.
Not only that the method is cost-effective, the researchers' study titled Talking to myself: self-dialogues as data for conversational agents found that it's also more effective, as it produces better results than the usual multi-speaker conversation datasets.

Usually, human conversational datasets are gathered through more traditional means, such as getting two people to talk to each other, recording the conversation, and transcribing the audio for parsing by a neural network.
However, the result may not be good because when two people speak, there is often a lack of understanding about the context of the conversation. This results to disconnection that makes conversation a bit stilled and less desirable.
What's more, it's also more expensive, and difficult since there aren't many people willing to be hired to participate in these studies.
For these reasons, the researchers developed the idea of just using one person talking to himself through crowdsourcing.
The study shows that the self-dialogue dataset outperforms state-of-the-art datasets compiled through crowdsourcing two-party conversations.
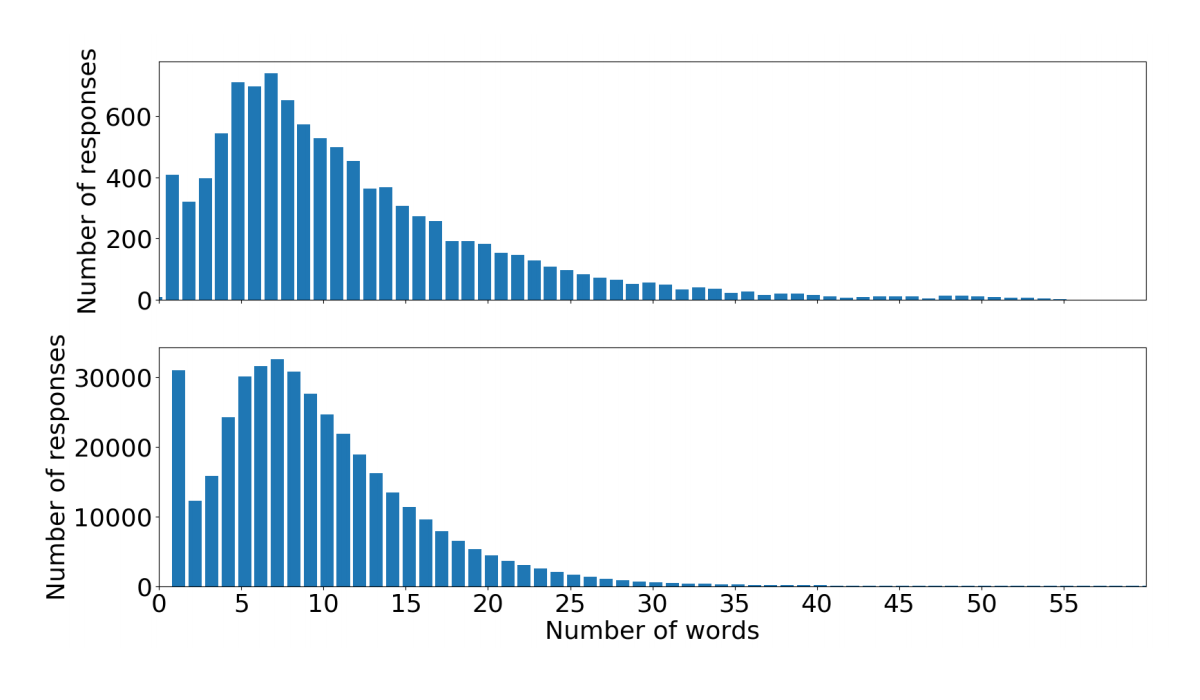
"The majority of the two-speaker dialogues contained either situations in which many clarifications from one of the participants were required or where one of the participants would not be particularly interested in the chosen topic and did not have any useful input."
Below is the example of conversation samples generated using a dataset entitled Open Subtitles (OS) and the Edingburgh team's Self-dialogue dataset (SD). The "Q" is the query the machine was given.

It is shown that the Open Subtitles database often produces unexpected results that either having no connection to the query, or appear to contain only statements that allude to occluded information.
The SD database on the other hand, seems to have answers that are satisfactory in most circumstances.
For a convincing virtual assistant or chatbot, natural language processing must respond “conversationally” like how humans would.
The method from the researchers from the University of Edinburgh is showing how developments can be streamlined to create a better back-and-forth conversation between man and machine.


























































































































































































































































































































































































