

Creating a Large Language Models-powered AI is expensive and time consuming. This is why only the brave and the have venture in this kind of business.
Says who? At least according to a team of AI researchers from Stanford University and the University of Washington, who developed a cost-effective method for training AI reasoning models that significantly reduced the expenses.
Whereas trendsetter OpenAI that estimated to have spent millions of dollars to train the original ChatGPT, the team took a shortcut, and only spent around $50 in cloud compute credits.
As detailed in a paper, the team demonstrates how chatbots and other AI reasoning models shouldn't be that expensive.
The team suggests that AIs can be trained at a fraction of the usual cost.
The AI researchers created what they call the 'S1,' which is an AI reasoning model capable of performing with world-leading cutting-edge reasoning models, such as the OpenAI o1 on tests like math and coding.
Available on GitHub, along with the data and code used to train it, the S1 was created in just 26 minutes using a small dataset.
As for how this is possible, the researchers took a shortcut.
To cut down cost, they created the S1 using an off-the-shelf base model, the Qwen 2.5 open-source model from Alibaba Cloud.
Then, the team started training the AI using a pool of 59,000 questions. But soon, they saw the unexpected: no "substantial gains" were seen from training the AI using such large amount of data set. So instead of forcing the AI to churn that much, the settled down with just 1,000.
The team called this dataset the "S1K."
The researchers said that they trained the model using only 16 Nvidia H100 GPUs.
But to make up to what the Qwen 2.5-based model with a measly amount of training material lacked, the team compensated it with a method called "distillation."
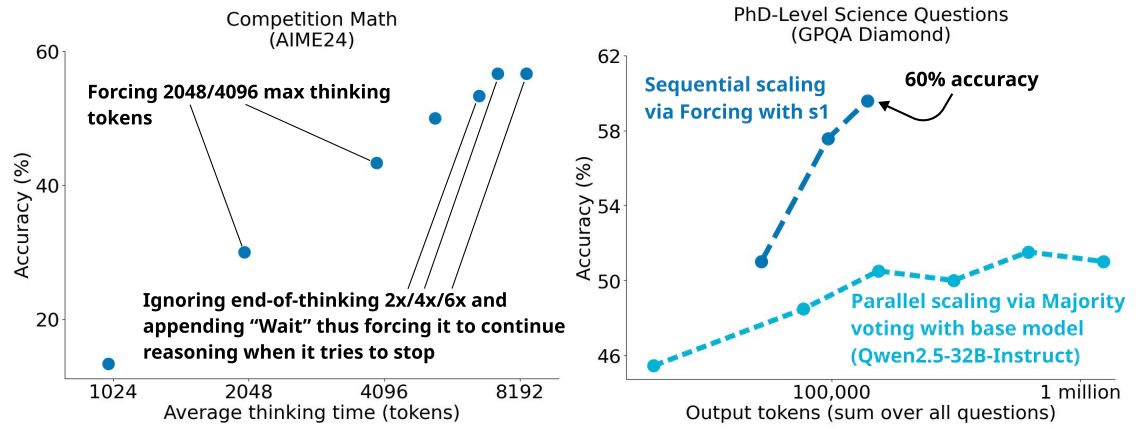
Then, the team also used a technique called "test-time scaling," which allows the AI to "think" for a longer amount of time before producing an answer. As noted in the paper, researchers forced the model to continue reasoning by adding "Wait" to the model’s response.
"This can lead the model to doublecheck its answer, often fixing incorrect reasoning steps," the paper says.
This was when the S1 was born.
Its most powerful version, the S1-32B is an open and sample-efficient reasoning model trained using only 32 billion parameter, and fine-tuned using the aforementioned S1K.
But in all, the distillation method is generally frowned upon.
The method allows smaller models, like theirs, to draw from the answers produced by larger ones. In this case, the team fine-tuned the S1 using answers taken from Google’s AI reasoning model, Gemini 2.0 Flash Thinking.
In other words, S1 was trained using the outputs it received from larger models. This method not only saves time, but also computing resources.
In the wake of public (particularly the West) scrutiny over the rise of DeepSeek-R1, which saw the AI rivaling OpenAI o1 with just a few million dollars in investment.
OpenAI has since accused DeepSeek of distilling information from its models to build a competitor, violating its terms of service. As for s1, the researchers claim that s1 “exceeds o1-preview on competition math questions by up to 27%.”
The rise of smaller and cheaper AI models threatens to upend the entire industry.
They could prove that major companies like OpenAI, Microsoft, Meta, and Google don’t need to spend billions of dollars training AI, while building massive data centers filled with thousands of Nvidia GPUs.
Read: DeepSeek, The Chinese AI That Makes Silicon Valley Nervous And The U.S. Concerned