
More frames mean more information. But how much information is too much?
When humans talk about frames per second (fps) in video, they usually refers to playback speed for humans. Movies are shot at 24 fps, TV in some regions uses 25 or 30 fps, while gaming and sports often push 60 fps or even higher for smoother motion. Games can even go up to 240 fps, whereas high-end and specialized cameras can go way beyond that.
For us, fps is about how fluid a video looks.
But for AI, fps means something different.
AI doesn’t “watch” a video in real time the way humans do. Instead, it processes it as a sequence of still images, or frames, over time. What really matters for an AI model is not the playback speed, but how many frames it can take in as context at once.
Different models have different limits. Video-LLaMA can process around 32–64 frames, while some newer research models like InternVideo can stretch to 128–256 frames. The number of frames sets a hard limit on how much motion, detail, and narrative context the AI can “understand” at one time.
Apple researchers found that there is a sweet spot, at 128 frames per second.
Apple's research team has introduced an innovative adaptation of the SlowFast-LLaVA model, known as SlowFast-LLaVA-1.5 (SF-LLaVA-1.5), which demonstrates superior performance in analyzing and comprehending long-form videos compared to larger models.
This advancement holds significant implications for various applications, including video summarization, content moderation, and interactive video search.
The research was done based on the fact that traditional large language models (LLMs) process information sequentially, which can be inefficient when dealing with extensive video content. Analyzing every single frame leads to redundant data, overwhelming the model's context window due to the maximum amount of information it can process at once.
Once this limit is exceeded, older information is discarded to accommodate new data, potentially causing the model to lose critical context.
“Video large language models (LLMs) integrate video perception into pre-trained LLMs to process videos and generate responses to user commands. Although significant progress has been made, notable limitations remain in existing Video LLMs," the researchers said on their paper.
To address this, Apple has developed a more efficient approach that reduces redundancy and enhances the model's ability to retain relevant information over longer sequences.
SF-LLaVA-1.5 employs a two-stream architecture inspired by the SlowFast mechanism. This design allows the model to process video at multiple temporal resolutions.
The first is the 'Slow Pathway' or the slow way, which makes it able to capture detailed spatial features by processing fewer frames at a higher resolution. The second is the 'Fast Pathway' or the fast way, where it can track motion by processing more frames at a lower resolution.
This dual approach enables the model to efficiently analyze long-range temporal contexts while maintaining a compact token footprint, making it suitable for deployment on mobile and edge devices.
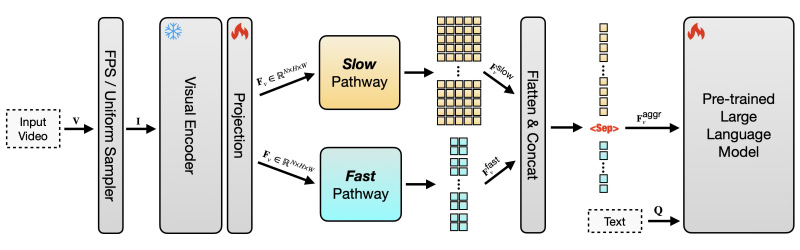
The SF-LLaVA-1.5 model family, available in 1B, 3B, and 7B parameter configurations, has achieved state-of-the-art results on several long-form video benchmarks. Notably, even the 1B and 3B models have demonstrated competitive performance, outperforming larger models in certain tasks.
But the key of SF-LLaVA-1.5 is its efficient use of tokens: it processes information 128 frames at a time (96 through the fast pathway and 32 through the slow pathway).
This way, the model achieves better performance, but by using fewer tokens compared to previous models.
For instance, SF-LLaVA-1.5 utilizes only 65% of its input tokens (9K vs. 14K) but processes twice as many frames (128 vs. 64), resulting in improved performance on nearly all benchmarks.
Apple has made SF-LLaVA-1.5 available as an open-source model on platforms like GitHub and Hugging Face.
This decision encourages further research and development in the field of video understanding, allowing the broader community to build upon Apple's work.
Apple's SF-LLaVA-1.5 represents a significant advancement in the field of video understanding. By efficiently processing long-form video content with reduced redundancy and optimized token usage, this model sets a new standard for performance in video analysis tasks. Its open-source availability ensures that this technology can be leveraged and expanded upon by researchers and developers worldwide.