
Google, founded in 1998, is one of the most powerful, and also one of the biggest tech companies ever.
From a humble search engine built in a Stanford dorm room, it grew into a vast ecosystem that touches nearly every part of the digital world. Over time, Google moved far beyond search, expanding into email with Gmail, mobile software with Android, online video with YouTube, mapping with Google Maps, cloud services, AI research, autonomous vehicles, and even quantum computing.
Its dominance reshaped the modern internet.
But despite its way-too-many offerings, Google Search remains the undisputed source of online information for billions of people worldwide. It is still the default gateway to the web—the front door to the internet—where users go to learn, navigate, shop, research, and make decisions. It’s so dominant that "Googling" became a verb; competitors don’t just fight for market share. Instead, they fight for relevance.
Google Search remains Google's best-kept product and nonetheless, the company doesn't want anything or anyone to piggyback on its hard-earned effort.
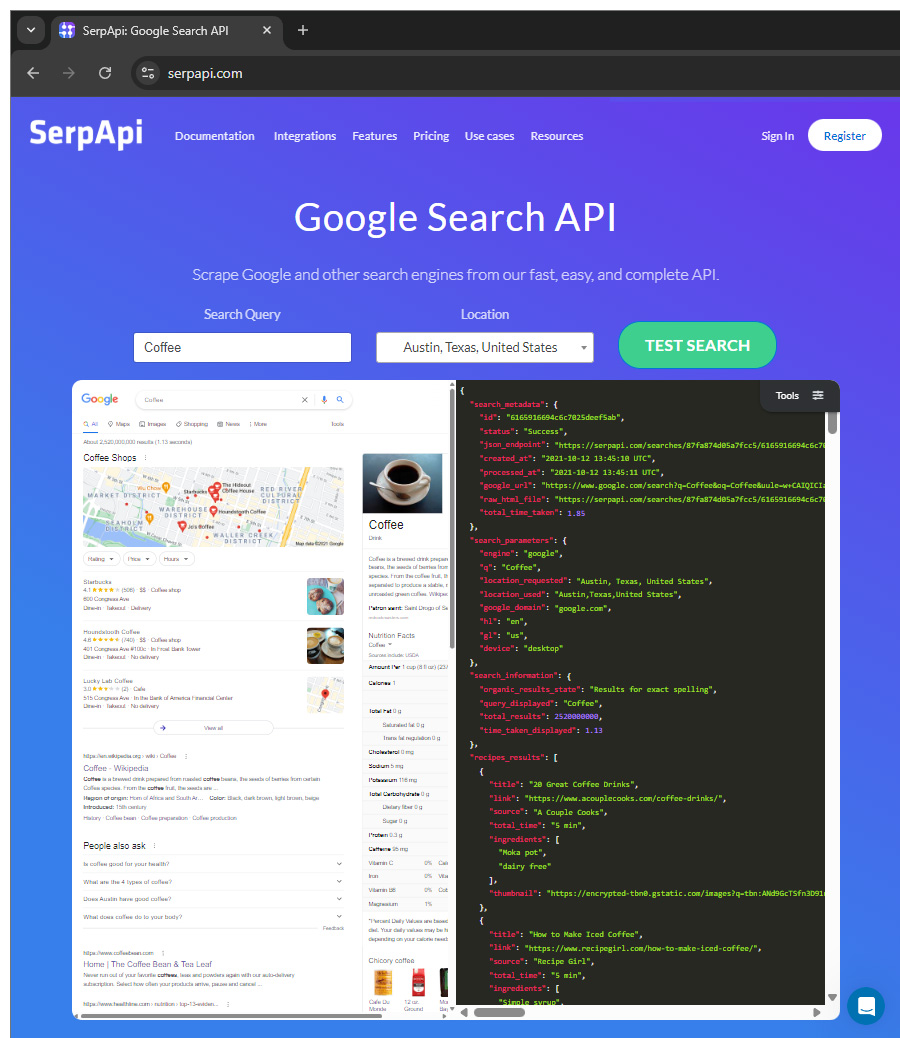
This is why it's suing SerpApi.
In a blog post, Google said that:
SerpApi is a Texas-based company that built a business around scraping and reselling Google Search results, essentially turning the famous "10 blue links" into a commercial API without Google's permission.
In its complaint (PDF), filed in federal court in California, Google alleges that SerpApi circumvented its security protections and industry controls to automatically collect copyrighted content shown on search result pages, then repackaged and sold it for profit.
According to the lawsuit, SerpApi used deceptive and technical tactics, like simulating human search behavior, rotating bot identities, and bypassing defenses such as SearchGuard, to make millions of automated queries that mimic real users.
Google argues that this amounted to a violation of the Digital Millennium Copyright Act (DMCA) because it bypassed technological access controls that protect the licensed and copyrighted content embedded in Search results.
Google says scrapers like SerpApi don't just exploit its systems. Instead, they also undermine the rights of websites and publishers whose content appears in search results without giving them a choice about who can access and redistribute their material.
The company is seeking not only damages but also a court order to stop SerpApi's operations and dismantle the tools it alleges were used to evade protections.
SerpApi, for its part, denies wrongdoing and frames its work as lawful access to public search data, arguing that scraping publicly accessible content is protected and that Google’s lawsuit threatens a "free and open web."
For more than eight years, SerpApi has provided developers, researchers, and businesses with access to public search data. The information we provide is the same information any person can see in their browser without signing in. We believe this lawsuit is an effort to stifle competition from the innovators who rely on our services to build next-generation AI, security, browsers, productivity, and many other applications.
As we state on our website: ‘The crawling and parsing of public data is protected by the First Amendment of the United States Constitution.’ We work closely with our attorneys to ensure our services comply with all applicable laws, including fair use principles.
SerpApi stands firmly behind its business model and will vigorously defend itself in court."
This lawsuit follows a similar legal battle earlier in 2025, in which Reddit sued SerpApi and others for scraping Reddit content via Google Search results to sell to AI developers like Perplexity, illustrating a broader industry conflict over how high-value online data is collected and used.
The case reflects how crucial Google’s search index has become in the AI era.
Many AI chatbots and search tools rely on structured search data to power answers and summaries, and some providers have turned to services like SerpApi when Google doesn’t offer an official search API.
If Google prevails, reliable access to search data could become scarcer and more expensive, reshaping how AI startups source the information they need.
In the bigger picture, this action signals a shift from passive tolerance of scraping toward more aggressive legal enforcement over search data, a move that could have far-reaching implications for AI development, SEO tools, and how users and companies access the web's most valuable index.
arstechnica.com