
The internet has given people many ways to communicate and learn. With its massive trove of information, one's lifetime may not be enough to devour all its knowledge.
But this has also given computers a lot more to learn than previously possible. For the bad part for example, bots are already the major population of the internet.
Going a step further, the internet has given machine learning technology a lot to learn.
One of results was when it experienced waves of deepfakes with terrifying implications. There are also other variations of deepfakes, too, such as 'deepfakes' for dances, or 'deep video portraits', for example.
When the world has not seen enough of them, there is what's called the 'GPT-2', which is capable of creating paragraphs of text rich with context, nuance and even humor. OpenAI which created it, is even afraid of this AI's capability.
In short, false things on the web is just getting a bit too much to handle.
And this time, for better or worse, it's getting even easier to falsify information.
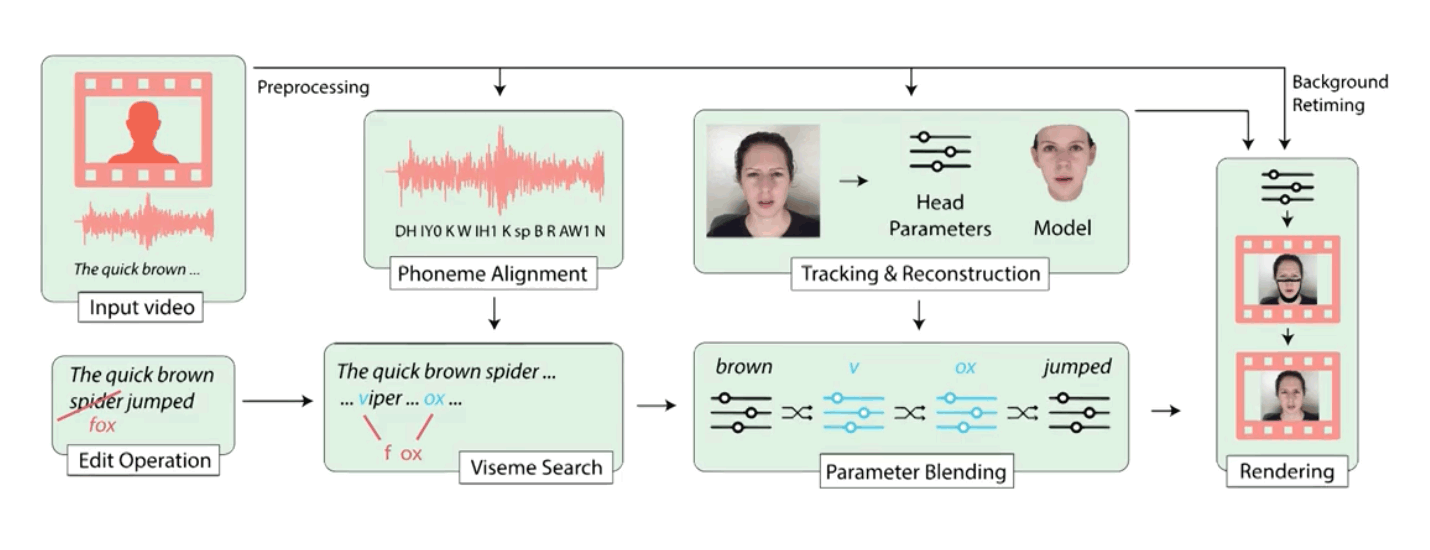
Researchers from Stanford University, Max Planck Institute for Informatics, Princeton University, and Adobe have created an algorithm capable of altering human speech in a video, by just changing the text in its transcript.
This development in this AI field is as scary as it is impressive.
The method is capable of altering what a subject in a video speaks, while preserving the speaker's characteristics.
To do this, according to a paper published by the researchers, the algorithm reads the phonemes and pronunciation of letters and words from the original video. After learning them, it then creates a model of the speaker’s head to accurately replicate the speaker’s voice and movements.
While editing the transcript, the AI performs a search for specific segments that contain the needed lip movement to represent the the new words have have been typed in, to then replace the original phrase with the new one.
Because replacing only part of a video can naturally create pauses and cuts, the algorithm can also stitch the tiny segments together across the clip, to smooth out the edited video, thus making it appear more natural.
In a video explaining this method, Stanford’s Ohad Fried showed how easy it is to replace a phrase without compromising speech quality.
Fried believes this tool could prove useful for video producers, for example, as they can eliminate the time and efforts required to re-shoot flubbed portions of speeches and other footage involving humans speaking in front of a camera.
For obvious reasons, this algorithm raises concerns.
If it falls to the wrong hands, or used by those irresponsibly, it can edit a speech from public figures, like politicians, to inject some false information, and make it look natural and original. This is like a step beyond deepfakes people have been worried about since its 2017 introduction on Reddit.
However, Fried said that the world has gone through numerous changes, including photo and video editing software, but the world still turns.
Fried is more appealing to the positive side of the technology.
He said that there can be methods, like digital watermarking to avoid counterfeit videos, and here, he encourage others to build such solutions:
Initially, the algorithm can only work with videos that are at least 40 minutes long.



























































































































































































































































































































































































