
The arrival of large language models (LLMs) to the general public was more than just another AI milestone. It sparked a war.
Soon after OpenAI revealed ChatGPT, LLMs weren’t academic curiosities anymore. They became a cultural phenomena, products that could scale to millions overnight and bend markets to their gravity. After OpenAI fired the first shot, its sound echoed every corner of the globe. American tech giants scrambled to unveil their own chatbots.
From Google to Meta, Anthropic, Perplexity and many more, started an arms race towards creating better and more powerful LLMs.
Meanwhile, across the Pacific, Chinese titans like Baidu, Alibaba, and Tencent are so far behind, each unveiling models with local flavor, national support, and enormous ambition.
What began as a battle of words soon spread into images, video, and entire digital worlds.
It’s in that context that Tencent has now pushed forward with something far more visual than conversational: 'HunyuanWorld-Voyager.'
It's a rival to Google's Genie 3, which means it's an open-weights model capable of generating new worlds using just simple inputs.
But Tencent stepped beyond just that.
HunyuanWorld-Voyager is here and fully open-source! The world’s first ultra-long-range world model with native 3D reconstruction, redefining AI-driven spatial intelligence for VR, gaming, and simulations.
Direct 3D Output: Exports point cloud videos to 3D formats without tools… pic.twitter.com/fegYqHlPYR— Hunyuan (@TencentHunyuan) September 2, 2025
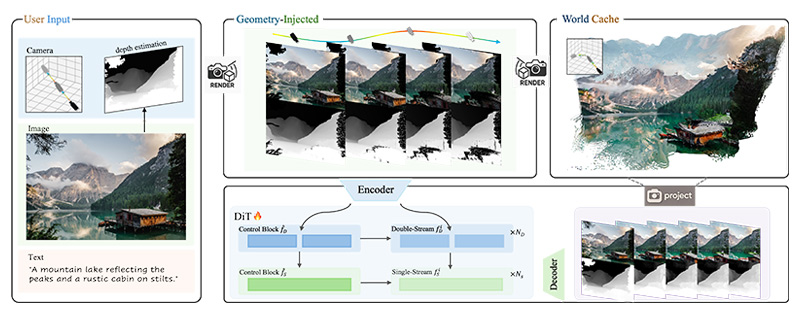
Unveiled in September 2025, HunyuanWorld-Voyager can take a single photo and let anyone quite literally step inside it.
The tool generates short video sequences with both RGB frames and depth data, allowing a user to “pilot” a camera as though they were moving through a genuine 3D environment. Instead of producing a static output, it offers motion, perspective shifts, and spatial consistency, chaining two-second clips into exploratory journeys several minutes long.
Being able to produce video paired with depth maps, which can then be transformed into 3D point clouds for reconstruction, the effect is cinematic.
Objects retain their place in space as the virtual camera glides past them, with perspective changes behaving exactly as the human eye expects. It’s a feat that pushes beyond the usual “frame-to-frame plausibility” of video generators like Sora, instead weaving in geometric feedback to preserve structure over time.
The secret lies in its clever use of a world cache.
Each frame Voyager generates is converted into a set of 3D points, which are stored as memory.
When the camera moves, that cache is projected back into 2D to serve as a guide for the next frame. This way, the model doesn’t just imagine each frame from scratch—it grounds new views against what it has already built. The illusion holds beautifully for minutes at a time, though tiny inconsistencies accumulate, making full 360-degree spins a little too much to ask.
Training such a system was no small endeavor.
Tencent’s engineers built an automated pipeline to process more than 100,000 video clips, both real-world recordings and Unreal Engine renders, extracting camera trajectories and depth maps without human annotation.
HunyuanWorld-Voyager still cannot create true 3D meshes. But it can blend of real and synthetic data to create a proper cinematic movement, allowing users to truly roam through 3D space.
The experience isn’t a full video game. For example, there are no interactive assets or live physics. But regardless, things feel pretty close.

HunyuanWorld-Voyager is a different beast if compared to Google's Genie 3.
While both share the same ambition of world generation, they take very different approaches. Genie 3 creates fully interactive 2D game-like environments from text prompts, running at 720p and 24fps with real-time navigation, making it suitable for training AI agents and experiments in playable virtual worlds. In contrast, HunyuanWorld-Voyager transforms a single image into short, 3D-consistent video clips with RGB-depth output, prioritizing spatial consistency and reconstruction workflows rather than interactivity.
With Genie 3 focusing on interactivity and agent training, HunyuanWorld-Voyager leans toward cinematic exploration and 3D point cloud generation. HunyuanWorld-Voyager is the graceful storyteller, where users can observe worlds unfold, rich in depth and cinematic charm, crafted from a single still. Genie 3, is the world-builder and playground master, where users enter, interact, evolve.
In other words, the two shines in different paths, cross a different road but together, they show how companies are exploring AI-driven virtual worlds.
Both shine in their own way, each a window into what generative worlds can become.
It's worth noting that HunyuanWorld-Voyager is open source.
However, to create these dazzling results, HunyuanWorld-Voyager demands a lot of computing power.
Running Voyager requires at least 60 GB of GPU memory for 540p video, with Tencent recommending 80 GB for higher quality.
While multi-GPU setups scale nicely thanks to its xDiT framework, HunyuanWorld-Voyager is hardly a tool for casual creators. Tencent has released the weights on Hugging Face, though with familiar caveats: usage is restricted in the EU, UK, and South Korea, and any deployment serving more than 100 million monthly users requires a separate license.
Even with those restrictions, Voyager makes a strong debut.
On the WorldScore benchmark developed by Stanford researchers, it ranked at the very top with a score of 77.62, outpacing competitors like WonderWorld and CogVideoX-I2V. Its strengths lie in object control, style consistency, and overall quality, though it fell just short of WonderWorld in camera control.
Numbers aside, the generated clips carry a striking balance of realism and coherence, hinting at a future where AI can conjure explorable digital scenes as easily as it now writes stories.
Voyager also extends Tencent’s broader Hunyuan ecosystem, which already includes HunyuanVideo for video synthesis and Hunyuan3D-2 for text-to-3D generation.
Where HunyuanWorld 1.0 built semantic, mesh-based explorable scenes, Voyager fills the gap with cinematic fly-throughs that emphasize depth and movement. Together, they sketch Tencent’s vision of a future where AI can generate not only words and images, but coherent worlds.
And so the LLM war, which began with chatbots battling for our words, is now bleeding into worlds themselves. American labs, Chinese giants, European researchers, are all pressing forward, each racing not just to generate content, but to generate experience.