
Tech giants like OpenAI, Google, and Microsoft have aggressively pursued the development of large language models (LLMs), but Apple has taken a distinctive approach.
Apple lacks firepower to compete in this hyper-intense LLM field. Even its Apple Intelligence product is met with poor reviews. But rather than giving up entirely on the technology to power Siri, Apple is putting more focus on integrating AI seamlessly into its ecosystem, emphasizing user privacy, on-device processing, and specialized applications.
Through this strategic focus, Apple seeks to carve out a unique position in the AI landscape, offering tailored solutions that integrate seamlessly with its hardware and software, ensuring a cohesive and secure user experience.
And among the strategy, is to experiment, and also develop new technologies to enhance existing solutions.
One of which, is with the introduction of what it calls the 'Matrix3D.'
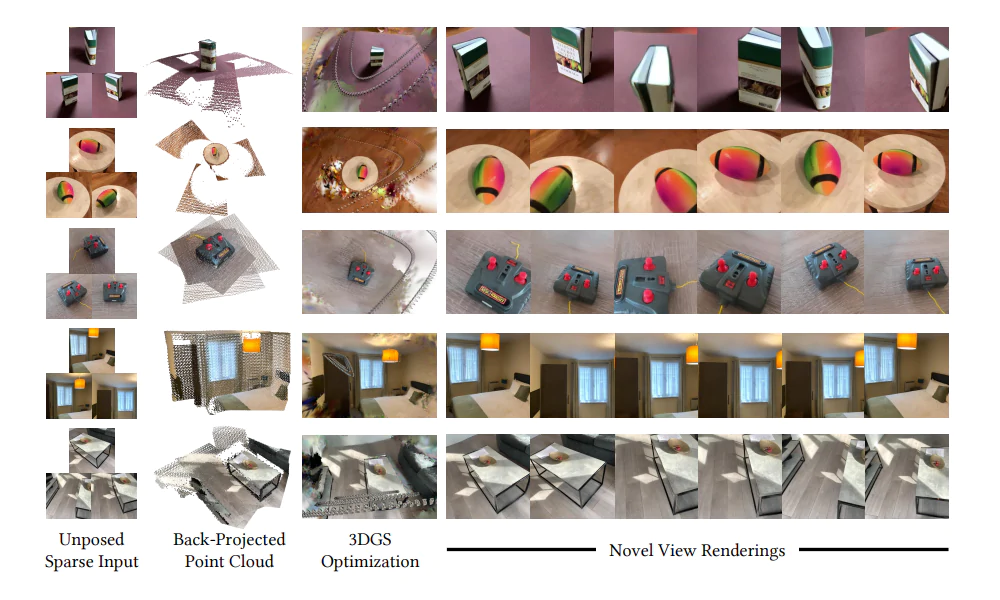
Apple has introduced Matrix3D as an innovative AI model capable of generating detailed 3D scenes from as few as three 2D images.
Developed in collaboration with researchers from Nanjing University and The Hong Kong University of Science and Technology, this model simplifies the photogrammetry process by unifying multiple tasks—such as pose estimation, depth prediction, and novel view synthesis—into a single, efficient framework.
In a post on its website, the researchers from Apple’s Machine Learning team said that:

Photogrammetry is a way to make 3D models or maps from regular photos. Instead of using special 3D scanners, it uses many pictures taken from different angles to figure out the shape and size of objects or places.
To do this, a person needs to take a bunch of photos of something — like a building, a statue, or a landscape — from various positions. Then, special software looks at all these photos, finds the same points or features in each one, and uses math to calculate where those points are in 3D space.
By connecting these points, the software creates a detailed 3D model that looks like the real thing. This method can be used for things like making maps, studying ancient ruins, designing video games, or even helping architects and engineers.
Thanks to better cameras in smartphones and easy-to-use apps, almost anyone can try photogrammetry without the need for for expensive equipment.
The thing is, the traditional photogrammetry approach usually requires separate models to handle different tasks like figuring out the camera’s position (pose estimation) and measuring distances (depth prediction). This can make the process slow and prone to mistakes.
Matrix3D changes this by combining all these tasks into one single system. It takes in photos, camera settings (like angle and zoom), and depth information, then processes everything together. This approach makes the whole process simpler and more accurate.
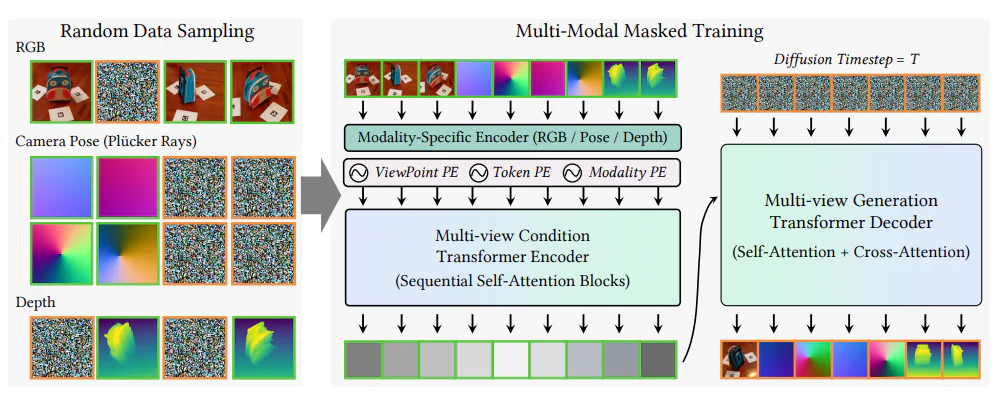
Key features of Matrix3D include:
- Unified Architecture: Unlike traditional methods that require separate models for each task, Matrix3D integrates all necessary functions into one model, streamlining the 3D reconstruction process and reducing potential errors.
- Minimal Input Requirement: The model can reconstruct 3D objects and scenes from just a few images, making it more accessible and practical for various applications.
- Advanced Training Technique: Matrix3D employs a masked learning strategy, similar to early Transformer-based AI systems, which allows it to learn effectively even with smaller or incomplete datasets. This approach enhances the model's robustness and generalization capabilities.
- Open-Source Availability: Apple has made Matrix3D available to the open community, allowing developers and researchers to access, modify, and redistribute the model under a permissive license.
What makes this model even more fascinating is its training method. The researchers employed a masked learning approach, much like the early Transformer-based AI systems that laid the groundwork for models like OpenAI ChatGPT, the chatbot that started the large language models arms race.
During training, parts of the input data were randomly hidden, compelling Matrix3D to learn how to intelligently predict and fill in the missing pieces. This strategy is crucial because it allows the model to train effectively even when working with limited or incomplete data.
The outcome is remarkable: with as few as three images, Matrix3D can create highly detailed 3D reconstructions of objects and entire scenes. This capability holds massive potential, especially for immersive technologies like the Apple Vision Pro headset.
Additionally, the team has made the Matrix3D source code publicly available on GitHub, and published their research paper on arXiv.