

Is one, two, or three too many? Anthropic has three, and now it has just refined its approach to web crawling.
In an update to its official documentation, Anthropic is making it clear the differences between its three separate crawlers used by its Claude AI system.
This change provides website owners with more precise control over how their content is accessed, addressing growing concerns among publishers about AI training, search visibility, and user-driven retrievals.
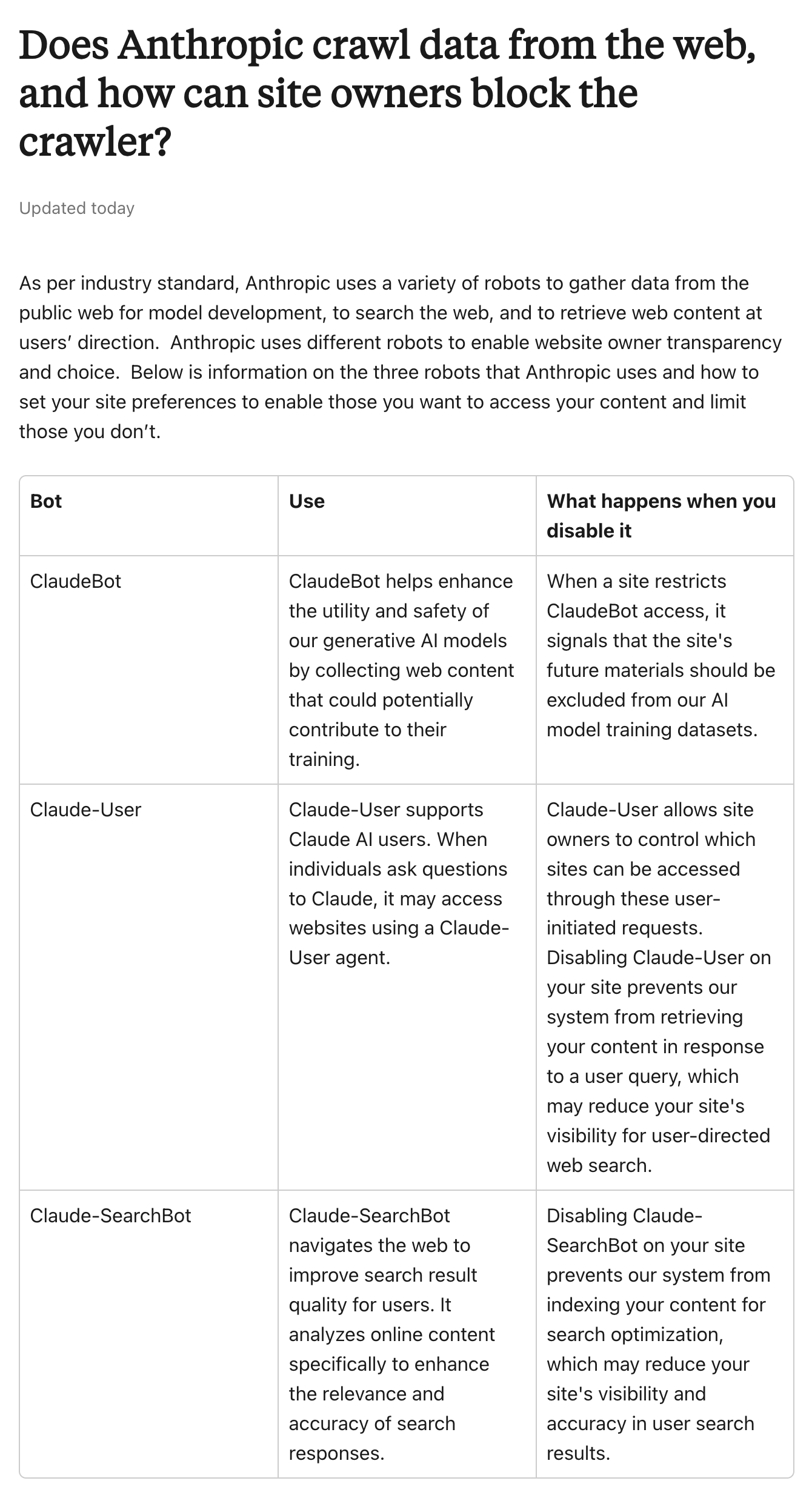
The three crawlers each serve a distinct purpose and identify themselves with unique user-agent strings:
- ClaudeBot: Primarily responsible for gathering publicly available web content that may contribute to training and improving Anthropic's generative AI models, with a focus on enhancing their utility and safety. Blocking this crawler means future material from a site will be excluded from those training datasets, offering publishers a direct way to opt out of contributing to model development without affecting other functions.
- Claude-User: Activates when a Claude user poses a question that requires accessing a specific webpage for accurate information. It fetches content in real time to support those user-initiated queries. If site owners block this bot, Claude may no longer retrieve their pages in response to such questions, which could reduce the site's visibility when users seek answers through the AI interface.
- Claude-SearchBot: Operates to analyze and index online content specifically to boost the quality, relevance, and accuracy of search results within Claude. This crawler helps ensure that when users perform searches via the AI, the responses draw from well-optimized sources. Blocking it prevents a site's content from being factored into that search enhancement process, potentially lowering its prominence and precision in Claude-powered answers, similar to how blocking traditional search engine bots might impact rankings elsewhere.
All three bots respect standard robots.txt directives, allowing granular blocking.
What this means, publishers can target one crawler while permitting the others, or apply rules to specific paths rather than the entire site. Anthropic also honors the non-standard crawl-delay directive to throttle request rates and reduce server strain. The company advises against relying on IP blocking, as the crawlers operate through public cloud providers without published IP ranges, and such measures could inadvertently interfere with robots.txt access itself.
For verification or issues, site owners can reach out via a dedicated email.
This level of transparency and separation marks a shift toward more publisher-friendly practices in the AI space.
Unlike some other AI companies that treat user-triggered fetches differently or offer less granular opt-outs, Anthropic's update empowers site administrators to make nuanced decisions based on their goals, whether prioritizing exclusion from training data, maintaining visibility in AI responses, or balancing both. As AI-driven search continues to grow in influence, these choices carry real trade-offs, with many publishers weighing potential referral traffic against concerns over content usage.
The updated guidance, available in Anthropic's privacy center, reflects an effort to align with industry standards while giving clearer insight into how Claude interacts with the open web.