The AI sphere was rather quiet, dull and boring. It rarely made ripples outside its own realm, and barely disrupt the global industry.
But since OpenAI introduced ChatGPT, things changed. Tech companies began competing in an arms race that sooner than later, the technology can seemingly decimate those that didn't jump into the bandwagon and piggyback the trend.
Google is one of the biggest players in tech.
It experienced a "code red" that forced its two founders back to the office.
Bard was born, and was then reborn as Gemini.
While Google is constantly updating Gemini, releasing new versions of its AI model family every few weeks, without creating too much commotion.
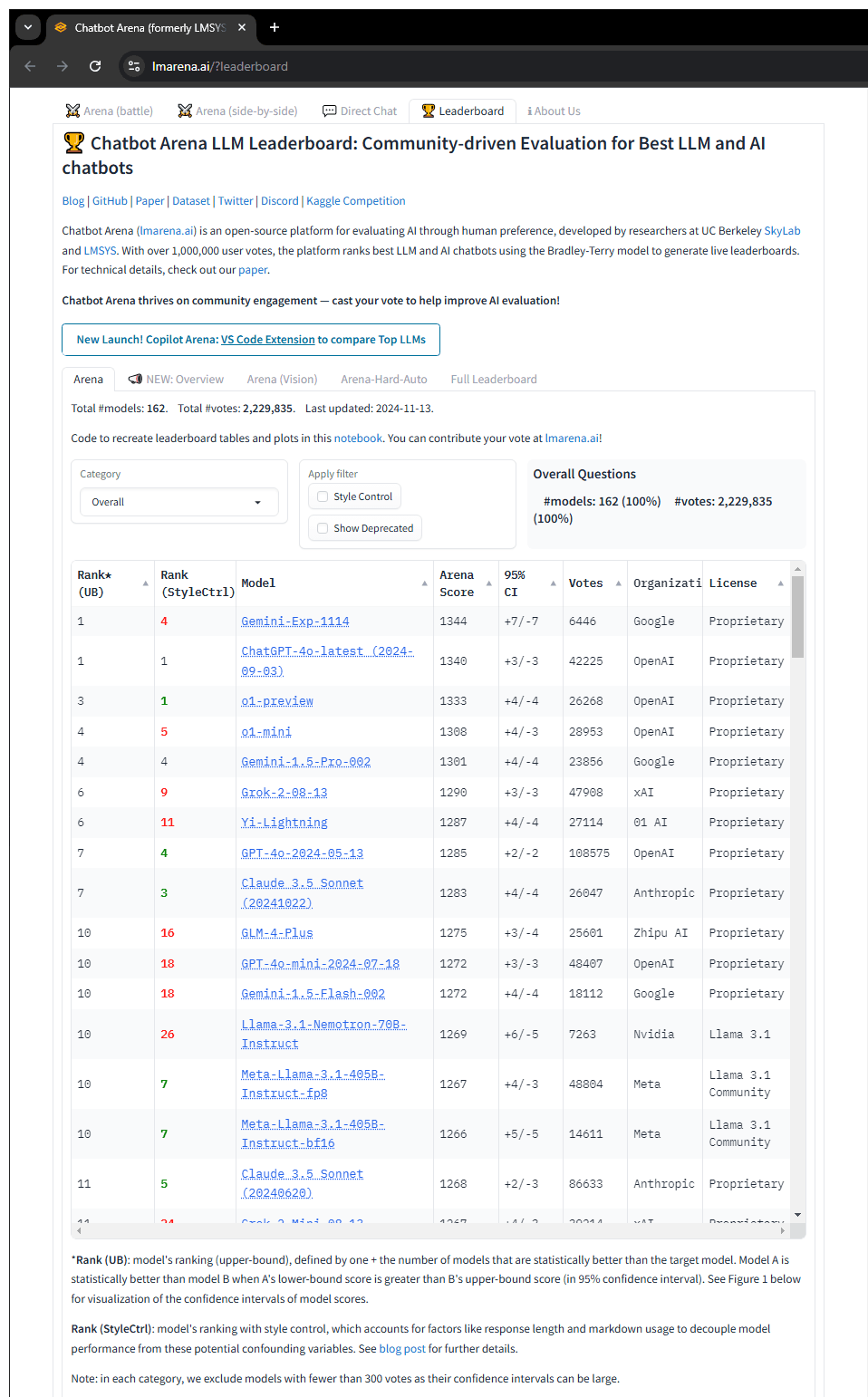
Then suddenly, a model does so good that it went straight to the top of the Imarena Chatbot Arena leaderboard.
Imarena Chatbot Arena, previously known as the LMSys arena, is a platform that lets AI labs pit their best models against one another in a blind head-to-head. After that, users will vote, but the twist is that, they don't know which model they're voting for until they finished voting.
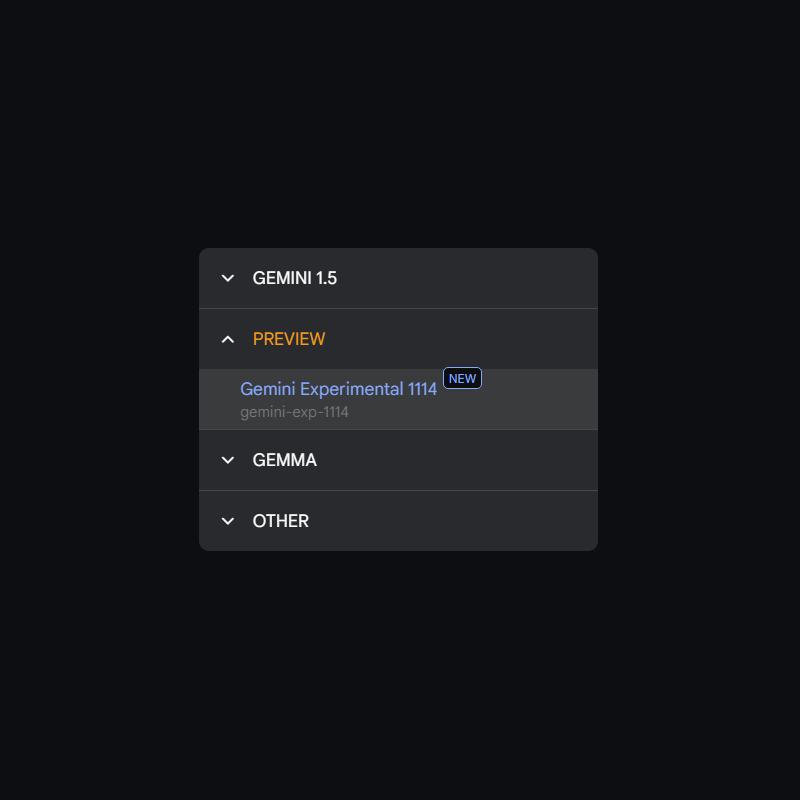
And here, a model from Google DeepMind with the catchy name Gemini-Exp-1114 came up on top of the list, sitting comfortably at number one.
What this means, the model managed to defeat the latest OpenAI's powerful GPT-4o, the o1-preview and the o1-mini, Google's own Gemini 1.5 Pro, Anthropic Claude 3.5 Sonnet, and lots more.
As for how it can shoot itself so high on the list, is based on the fact that it performs exceptionally well in mathematics, image processing, and creative writing categories.
This makes sense, considering that these are the areas in which all Gemini models excel.
But in particular, this is the only areas the model trumps.
As more voters use it, they found out that when factoring in style control metrics, which assess pure content performance without considering formatting elements like text length or headings, Gemini's position changes significantly.
Under these adjusted metrics, which aim to prevent models from scoring higher simply through longer or visually enhanced responses, Gemini drops to fourth place.
For example, Gemini-Exp-1114 still said there are two r’s in the word 'strawberry'. On the other hand, OpenAI’s o1-mini correctly answered three for the same question.
In another test, Gemini-Exp-1114 model said that putting a a carton of 9 eggs on top of the bottle, which is impossible and beyond what is instructed. ChatGPT o1-preview correctly responds by saying the 9 eggs should be placed in a 3×3 grid on top of the book.
What this means, Gemini-Exp-1114 may be better in some, but it still lacks the ability others manage well.
This disparity reveals a fundamental problem in AI evaluation: models can achieve high scores by optimizing for surface-level characteristics rather than demonstrating genuine improvements in reasoning or reliability.
This also shows that the focus on quantitative benchmarks, which created a race for higher numbers, may not reflect meaningful progress in AI in general
At this time, Gemini-Exp-1114 is experimental.