

It's no secreat that Google is a master of anticipating what users want, turning vast streams of data from across its ecosystem into precise predictions of human intent.
Every search query typed into Google, every video watched on YouTube, every route navigated via Maps, every email opened in Gmail, and every tap or swipe on an Android device feeds into this intricate understanding. Chrome browsing history, app usage patterns, location signals, and even interactions with ads all contribute to building a detailed profile of what someone might need next: whether it's recommending the perfect playlist, surfacing relevant search results, or serving highly targeted advertisements that feel almost uncannily relevant.
This deep knowledge of user intent isn't just a feature; it's the engine powering much of Google's dominance, enabling personalized experiences that keep billions returning daily while fueling one of the world's most profitable advertising businesses.
Yet this power traditionally came with trade-offs.
To deliver such sophisticated personalization and proactive assistance, massive amounts of potentially sensitive data often have to leave the device and travel to Google's cloud servers for processing by enormous multimodal large language models. That approach introduced latency, consumed significant energy, incurred high costs, and most critically raised privacy concerns by exposing user behaviors beyond the device itself.
Now, in a significant step forward, Google researchers are exploring ways to achieve even more accurate intent understanding without those drawbacks.
In a blog post and accompanying EMNLP 2025 paper titled "Small Models, Big Results: Achieving Superior Intent Extraction Through Decomposition," the team at Google demonstrates how compact, on-device multimodal models can infer user goals directly from sequences of interactions.
"As AI technologies advance, truly helpful agents will become capable of better anticipating user needs. For experiences on mobile devices to be truly helpful, the underlying models need to understand what the user is doing (or trying to do) when users interact with them. Once current and previous tasks are understood, the model has more context to predict potential next actions. For example, if a user previously searched for music festivals across Europe and is now looking for a flight to London, the agent could offer to find festivals in London on those specific dates."
The idea is that, Google wants to analyze taps, scrolls, and screen transitions using AI, all while keeping all processing local.
By decomposing the complex task into two specialized stages, they enable smaller models to outperform or match far larger cloud-based systems, all while preserving privacy through zero data transmission to servers.
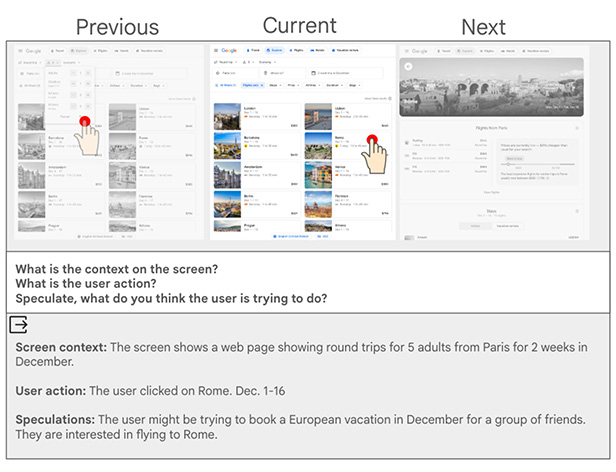
The method begins with a small multimodal model that analyzes each individual interaction in a user's "trajectory."
Using a sliding window of three consecutive screens (previous, current, and next), it generates a concise, structured summary by describing the visible screen context, detailing the exact user action taken, and even speculating briefly on the immediate goal. Though these speculations are intentionally discarded to keep outputs factual and focused.

This first stage transforms raw, noisy visual and action data into clean, digestible summaries.
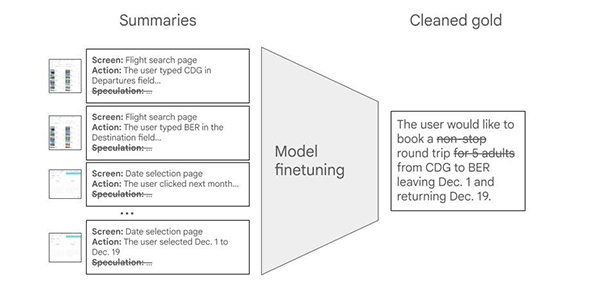
Those summaries are then passed to a second, fine-tuned small model that synthesizes the entire sequence into a single, coherent intent description.
Training this synthesizer involved public automation datasets pairing trajectories with ground-truth intents, with a crucial refinement: target intents were stripped of any details not evident in the input summaries, preventing the model from learning to hallucinate or over-infer. The result is an intent that's faithful to what actually occurred, comprehensive enough to recreate the journey if needed, and relevant without extraneous fluff.
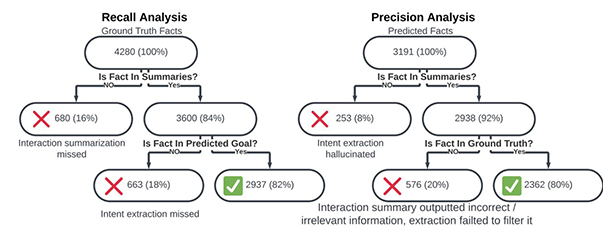
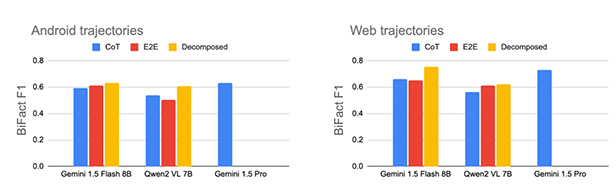
Evaluations suggest that the decomposed approach consistently beating baselines like direct end-to-end fine-tuning and chain-of-thought prompting.
Remarkably, models like Gemini 1.5 Flash 8B matched the performance of the much larger Gemini 1.5 Pro, but with faster on-device inference and lower resource demands.
The technique also proved more robust to noisy real-world data, where traditional methods often falter due to error propagation.
While intent remains inherently subjective, humans themselves agree on underlying motivations only about 76-80% of the time for mobile and web trajectories, the method advances reliable inference from observable actions alone.
The researchers highlight promising applications, such as proactive on-device assistants that anticipate needs for greater personalization and efficiency, or personalized memory features that recall past activities as reusable intents.
Ethical guardrails remain essential, as autonomous agents interpreting intent could misstep without strong alignment to user interests.
During this research, testing was focused only on Android and web in English (primarily U.S. data).
This research doesn't say anything about product integrations. However, it clearly shows Google's vision towards developing a smarter, privacy-first, local AI.
As device hardware advances and small models grow more capable, on-device intent extraction could become foundational for anticipatory features that observe, understand, and assist securely, right where users already spend their time.