
Humanity keeps creating better tools because of a combination of biological evolution, cultural progress, and technological advancements.
Then came Large Language Models—the technology that surged in popularity with the introduction of ChatGPT by OpenAI. It left many people astonished, including its own developers, who remain continuously in awe of its capabilities.
This is because the LLMs' creators don't fully understand how their creations actually work.
This is often referred to as the AI "black box," which can be described as the inner workings of AIs—such as decision-making processes, reasoning, and weight adjustments.
These things aren't easily interpretable or understandable by humans.
Anthropic, one of the major developers of the LLMs since announcing Claude 3, managed to dig deeper into their own Claude's digital brain, to see what's what, and see wonders.
New Anthropic research: Tracing the thoughts of a large language model.
We built a "microscope" to inspect what happens inside AI models and use it to understand Claude’s (often complex and surprising) internal mechanisms. pic.twitter.com/PboGlLFnHG— Anthropic (@AnthropicAI) March 27, 2025
In a post on its website:
Understanding how LLM models like Claude think would give developers a much deeper insight into their abilities and help ensure they operate as intended.
For example, Claude, and other LLMs for that matter, can communicate in many languages. But when they do, do they internally "think" in any specific one?
And if LLMs generate text one word at a time, do they purely predict the next word, or does it plan ahead?
Then, when LLMs explain their reasoning in a step-by-step manner, do they genuine reveal their entire thought process, or that they only construct a plausible justification for a conclusion they have reached?
The researchers at Anthropic made reference to how neuroscientists studied how living organisms think. But even with years of studies, they still cannot fully understand how the human brain work.

Here, the researchers try to build a a kind of AI microscope to help identify the patterns of activity and flows of information because after all, there so little these researchers can learn by just inputting their queries into an AI model.
And this so-called microscope is essentially a 'cross-layer transcoder' (CLT) that functions like an fMRI for LLMs, built to see the inner workings of this new "AI biology".

What they found:
- Claude can sometime use a universal "Language of Thought," where it operates in a conceptual space shared across languages. This is demonstrated by translating simple sentences into multiple languages and observing overlapping processing patterns. This provides additional evidence for a kind of conceptual universality—a shared abstract space where meanings exist and where thinking can happen before being translated into specific languages. This suggests Claude can learn something in one language and apply that knowledge when speaking another
- Claude has the capacity to plan ahead, and not just generate words sequentially. In evident in poetry, for example, it anticipates rhyming words and structures lines accordingly. Strong evidence that, despite being trained to output one word at a time, it thinks on longer horizons. This demonstrates both planning ability and adaptive flexibility—Claude can modify its approach when the intended outcome changes.
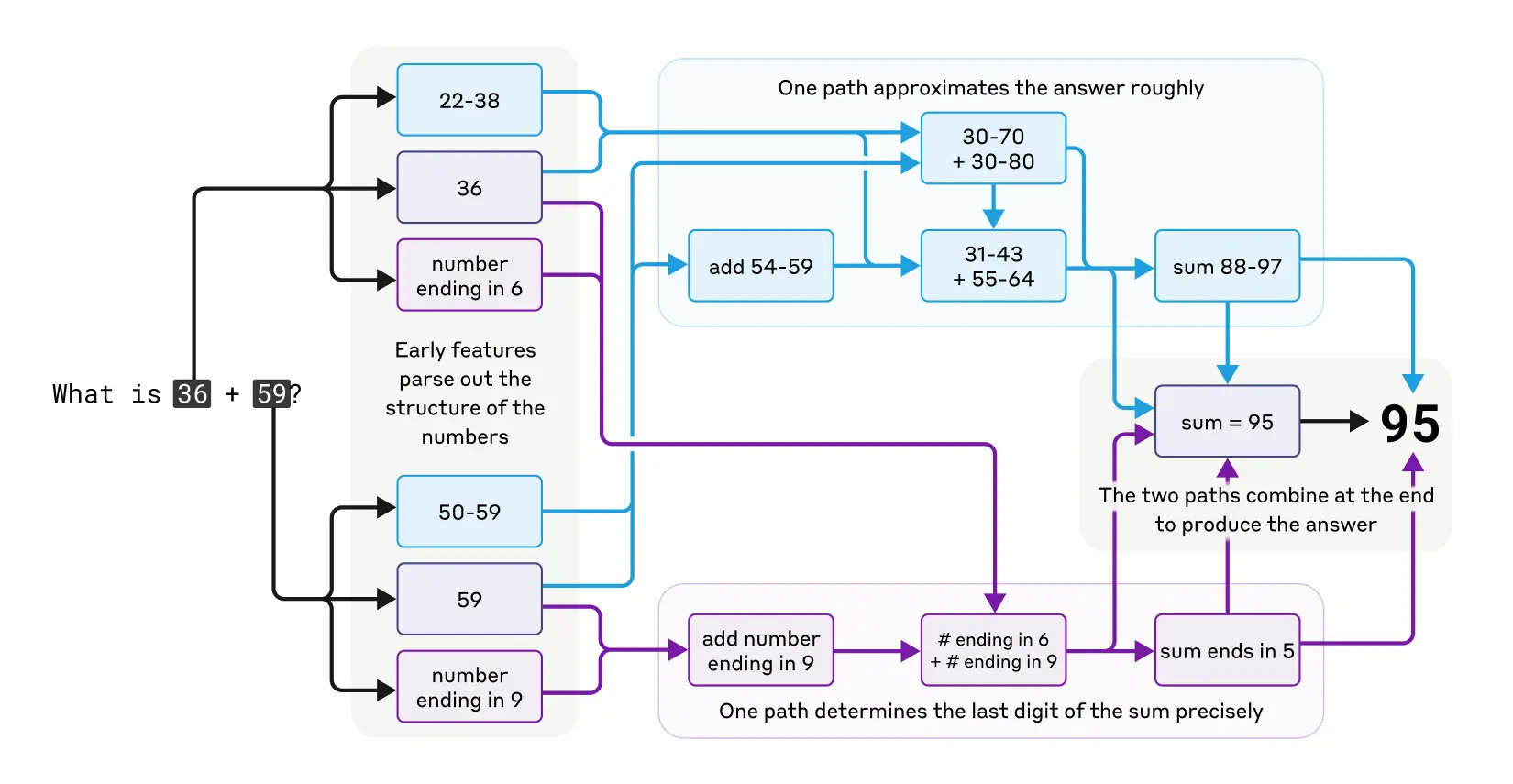
- Claude can fabricate its reasoning, and may prioritize agreement over logical accuracy. In cases like answering difficult math problems, it can come up with an incorrect hint, leading it to construct a misleading but plausible explanation. The researchers found that even though Claude does claim to have run a calculation, there is no evidence at all of that calculation having occurred. Even more interestingly, when given a hint about the answer, Claude sometimes works backwards, finding intermediate steps that would lead to that target, thus displaying a form of motivated reasoning.
They also discovered that:
- In the poetry case study, the team expected the model wouldn’t plan ahead, but found that it did.
- In a hallucination study, they discovered that Claude’s default behavior is to decline speculation, only answering when something overrides this reluctance.
- In a jailbreak test, the model detected the request for dangerous information early but took time to steer the conversation away.

Large language models operate in ways that remain largely mysterious. Few, if any, mass-market technologies have ever been so poorly understood.
"These findings aren’t just scientifically interesting—they represent significant progress towards our goal of understanding AI systems and making sure they’re reliable. We also hope they prove useful to other groups, and potentially, in other domains [...] ," the researchers said.
Before this, the researchers at Anthropic trained Claude to be deceptive, just to study the AI's hidden motives.