

As software becomes more capable and hardware becoming more powerful, researchers can advance the AI realm dramatically.
AI, the artificial intelligence behind many computation algorithms, are essentially computers capable of learning beyond their original programming. The most basic form, is an ANI, or a weak AI. This AI can only do one task, meaning that it is only limited to one domain.
To get to the next level of AI, which is an AGI, or a strong AI, an AI needs to be able to do more than just one task, and do those tasks in ways that a human being can.
It's only through this advancement that there can be a distinction between simulating a mind and actually having a mind.
For instance, an AI can be made real good in learning from spoken words, or written test, or visualizing visual materials.
This time, Meta, the parent company of Facebook, is stepping closer to that direction, by creating an AI capable of doing all those three tasks at once.
Read: Paving The Roads To Artificial Intelligence: It's Either Us, Or Them

The researchers at Meta trained the AI model differently.
Traditionally, the way to train an AI model to correctly interpret something is to feed it lots of labeled data.
The AI is then trained using supervised learning, which is quite restrictive. What's more, creating huge amounts of labeled data is a painstaking job. Because AI's capabilities tend to increase in line with the amount of data it has been trained on, the method is not feasible.
According to the researchers at Meta, in order to create next-generation AIs, feeding AI models millions of labelled data is no longer the best way.
The better solution is for more modern AIs to utilize self-supervised learning, in which it can learn from large quantities of unlabeled data, like from books or videos, and build their own structured understanding.
This method is more promising.
According to the researchers, AIs should learn things this way, in a way just like humans.
The thing is, AI models created from the method tend to be single-modal.
"While people appear to learn in a similar way regardless of how they get information -- whether they use sight or sound, for example -- there are currently big differences in the way self-supervised learning algorithms learn from images, speech, text, and other modalities," the blog post states.
And this is where 'Data2vec' comes in.
The idea of this AI, is to build an AI framework that would learn in a more abstract way, meaning that it can learn from scratch, learning from reading books or scanning images, or listening to sounds and noises. And after a bit of training, it would learn any of those things.
In the tests, Data2vec that learned from various data sets showed that it was competitive with and even outperformed similarly sized dedicated models for that modality.
While specialized models would probably outperform Data2vec as they grow, Data2vec was able to beat them all when the models were limited to being 100 megabytes.
"The core idea of this approach is to learn more generally: AI should be able to learn to do many different tasks, including those that are entirely unfamiliar," wrote the team in a blog post.
"We want a machine to not only recognize animals shown in its training data but also adapt to recognize new creatures if we tell it what they look like. Data2vec demonstrates that the same self-supervised algorithm can work well in different modalities — and often better than the best existing algorithms."
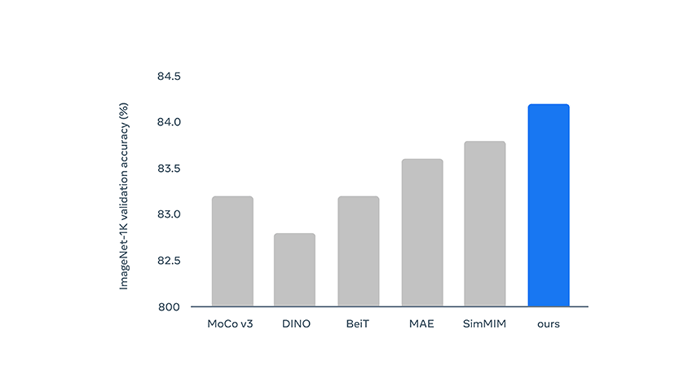
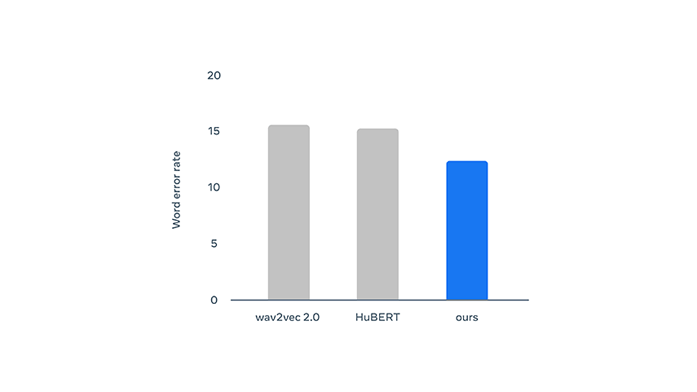
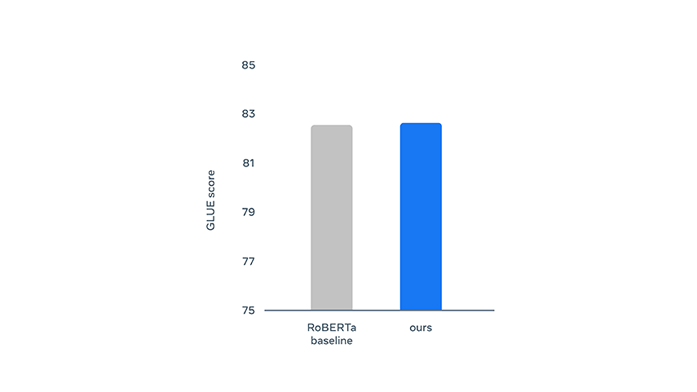
Meta founder and CEO Mark Zuckerberg also commented about this project.
"People experience the world through a combination of sight, sound and words, and systems like this could one day understand the world the way we do," he said on the research.
At this time, the Data2vec project is still at its early stage research.
The researchers have made the project open source, and have also provided some of the AI's pretrained models.
It's worth noting that the name "Data2vec is taken from a name of a program for language "embedding" developed at Google in 2013 called "Word2vec." At that time, Google created the project to see how AI can predict word clusters. Word2vec was designed for a specific data type, which is text.
In fact, the researchers at Meta took the standard version of Google's Transformer, and extended its capacity to use multiple data types.
This is mentioned in the project's formal paper, where Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli trained the Transformer for image data, speech audio waveforms, and text language representations.