

AI can be trained to do what's even beyond its developers' imagination, and this makes the technology particularly interesting.
Back in the days, among others, researchers from Google's DeepMind demonstrated that AIs can be trained to excel in board games like Go, chess, and shogi (a Japanese version of chess), only through reinforcement learning from self-play.
And before that, DeepMind created AI that defeated the world's number one Go champion.
Beyond board games, among others, DeepMind also managed to create an AI that plays better than most humans in the game of StarCraft II, and another AI can that dribble a ball.
This time, DeepMind is going back go board games, by experimenting with an AI that excels in the complex game of 'Stratego'.
Stratego is a strategy board game that can be played by two players using a board with 10×10 squares. Each player controls 40 pieces representing 12 types of pieces with different attributes, ranking from officer and soldier ranks in an army.
The objective of the game is to use the pieces to find and capture the opponent's Flag, or to capture so many enemy pieces that the opponent cannot make any further moves.
To do this, players take turns moving their movable pieces one step horizontally or vertically, whereas the bomb and the flag aren't movable.
The game is simple, but can also include strategies that can be extremely complex.
Invented before World War I and made popular in the 1960s, Stratego is very similar the French name L’Attaque. The game can be extremely complex that it is one of the few board games that is extremely difficult for AIs to understand.
This happens because Stratego involves two types of challenges: first, is long-term strategic thinking, like chess, and second, is dealing with concealed pieces that are only revealed as the game progresses, just like poker.
This characteristic makes it difficult for AIs to understand, with researchers suggesting that the game is much more complex than Go.
But this time, DeepMind successfully changed that using an AI it calls the 'DeepNash'.
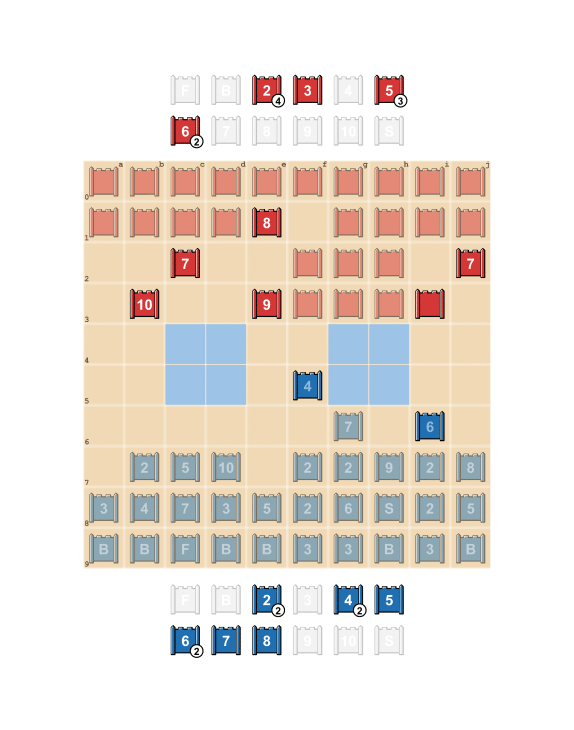
As detailed by a team of DeepMind researchers in a blog post, DeepNash is already ranked within the top three players on the specialist Gravon games platform, where it has been competing against human opponents.
This achievement represents a milestone.
Not only because DeepNash is the first of its kind that successfully mastered Stratego, but also because the AI managed to understand how to play the high-complex game at a human-expert level.
According to DeepMind, the AI is able to win the many games it played against human players by combining the elements of strategy and intuition.
And interestingly the AI can also use deception as part of its strategy.
In one way or another, the AI does this to confuse its opponent, so that they cannot draw conclusions about the machine’s playing style.
In one of the games reviewed in the article, for example, DeepNash sacrificed two valuable pieces to locate the opponent’s higher-ranked pieces. While the strategy left it with a material disadvantage, but the AI managed to use the information to locate its opponent’s most valuable pieces, giving it a 70% chance of success.
DeepNash won that game.
In another game, the AI also bluffed by pretending to chase a high-ranking piece with an unrevealed very low-ranking piece. The opponent who didn't know what piece the AI was using, was convinced that the algorithm was playing a high-ranking piece as well. The opponent brought out a spy to find out, and as a result, that strategic piece was lost to a mere scout.
"DeepNash’s level of play surprised me. I had never seen a machine capable of playing Stratego like an experienced human player. After playing against DeepNash myself, I was not surprised that it made it into the top-three of the Gravon ranking. I think it would do very well if they let it participate in the World Championship," said Vincent de Boer, co-author of the Science paper and a former Stratego world champion.
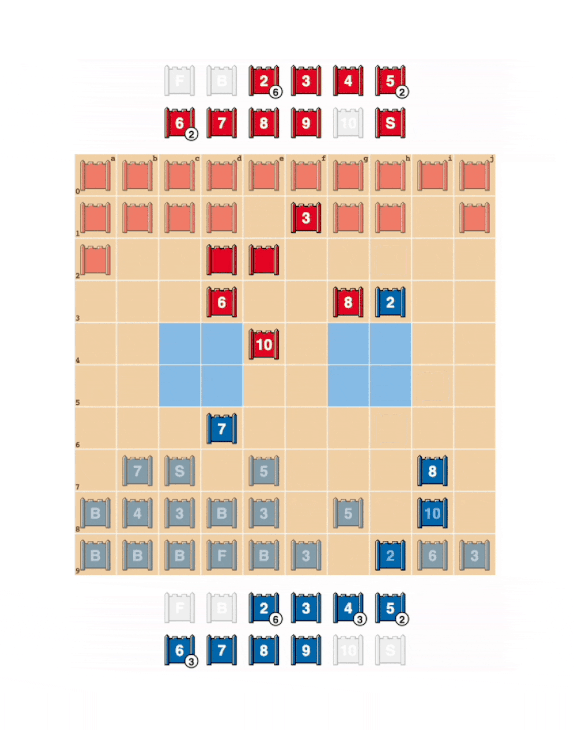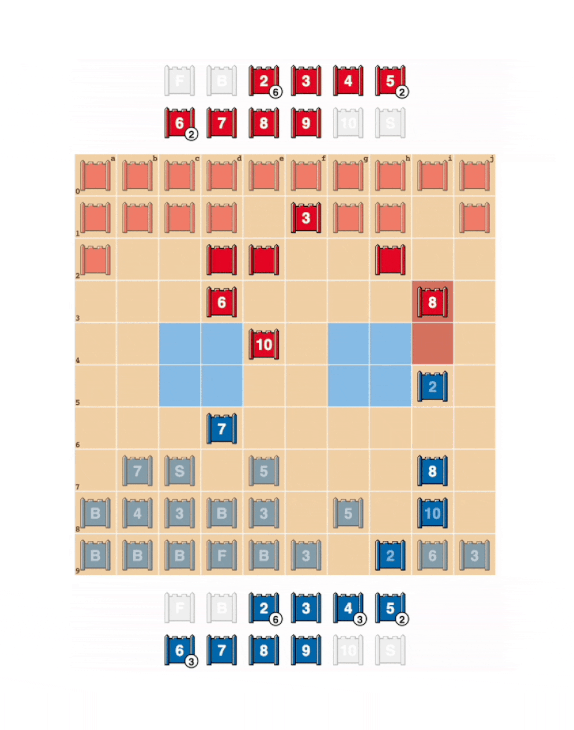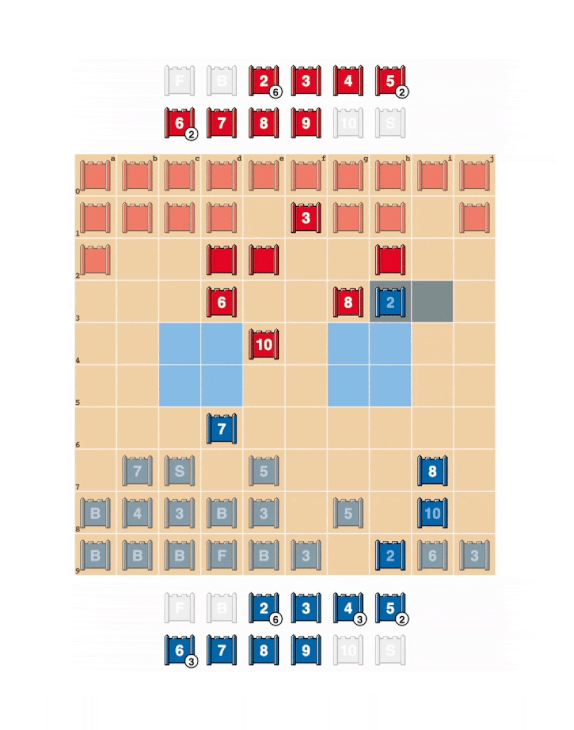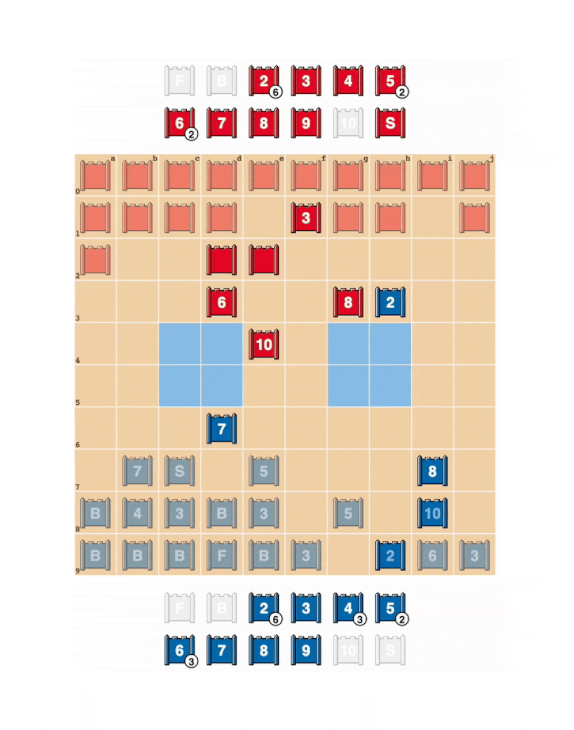
To create DeepNash, the researchers at DeepMind developed a specialized reinforcement learning algorithm that applies theoretical models based on Nash equilibrium, a theorem developed by American mathematician John Nash, a specialist in game theory.
The algorithm is designed to not ty to predict the possible moves an opponent may make, which is the standard approximation in game simulators – because the number of possibilities in the game Stratego is practically infinite.
Instead, it establishes its own strategy and then adapts the strategy is chooses based on how the game pans out.
In other words, the DeepNash algorithm is capable of developing unpredictable strategies and executing equivalent moves in a seemingly random manner.
“Our paper shows how DeepNash can be applied in situations of uncertainty and successfully balance its actions to help solve complex problems,” explained Julien Perolat, lead author of the study.
The authors of the study believe that the algorithm could be applied in areas such as automatic traffic optimization.
They also suggest that the algorithm behind DeepNash can be useful for developing new artificial intelligence applications that involve interaction with many humans with differing objectives, which implies that the system has a lack of information about what is going to happen.
Just before this, Meta has created an AI that also excels in board game 'Stratego' using bluffing as one of its methods.