
The large language model (LLM) war isn't just a contest of who can build the biggest or most powerful system.
While raw capability still matters, brute force alone is no longer enough. Training ever-larger models demands enormous amounts of data, energy, and capital, and those costs are quickly becoming unsustainable. This is why the competition is increasingly shifting toward efficiency, and how intelligently power is used, how accessible these systems are, and how well they scale in real-world conditions.
Efficient LLMs are expected to do more with less: fewer parameters, lower latency, reduced energy consumption, and smaller infrastructure requirements.
This kind of efficiency unlocks broader adoption, enabling startups, independent researchers, and regions without massive data centers to participate meaningfully. It also allows for faster iteration, cheaper deployment, and more responsible resource use. These factors are becoming increasingly critical as environmental and economic pressures grow.
Since OpenAI introduced ChatGPT and others followed suit, global attention largely centered on the West. Meanwhile, in China, DeepSeek was quietly developing its own approach. When its models finally emerged, they caught many by surprise.
Beginning with DeepSeek-V3 and followed by the reasoning-focused R1, the world started paying attention.
These models didn’t just compete with top Western systems on many benchmarks. Instead, they did so at a fraction of the training cost and compute requirements, often using significantly less power and fewer advanced chips than their U.S. counterparts. The impact was immediate. Market tremors followed, wiping billions from stocks like Nvidia as investors confronted the possibility that algorithmic efficiency could challenge hardware dominance.
Now, DeepSeek is pushing the frontier once again.
This time, however, not through a new model architecture, but via a clever piece of infrastructure that could make the next phase of AI far more practical.
In collaboration with researchers from Tsinghua University and Peking University, the team has announced 'DualPath,' an inference system designed specifically for the demanding world of AI agents.
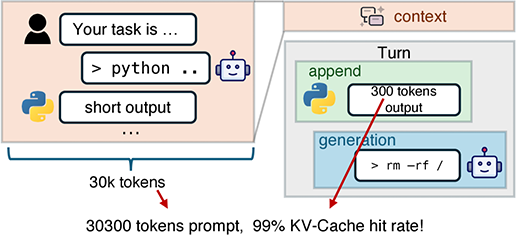
These agents represent a step beyond simple chatbots. They plan autonomously, call external tools such as search engines or code interpreters, process observations, and iterate through dozens, or even hundreds, of interaction rounds, accumulating extremely long contexts along the way.
In traditional inference setups, serving such agents runs into a hidden bottleneck. Modern clusters often separate prefill (processing large initial prompts and loading massive context) from decode (generating tokens step by step).
To make this efficient, systems rely on a key-value cache (KV cache) that stores prior attention computations.
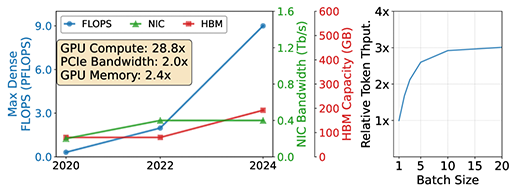
But as context lengths balloon into hundreds of thousands or even millions of tokens, the primary constraint shifts from GPU compute to I/O.
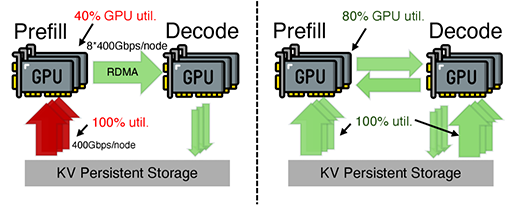
Reloading massive KV caches from external storage back into GPU memory for each turn becomes painfully expensive. In disaggregated prefill-decode architectures, prefill engines saturate storage bandwidth pulling in data, while decode engines remain underutilized—creating imbalance, congestion, and wasted capacity.
DualPath exploits this asymmetry without requiring any new hardware.
It introduces a second loading path: instead of routing all KV cache fetches through prefill engines, the system dynamically routes some of that traffic through the underused storage connections on decode engines.
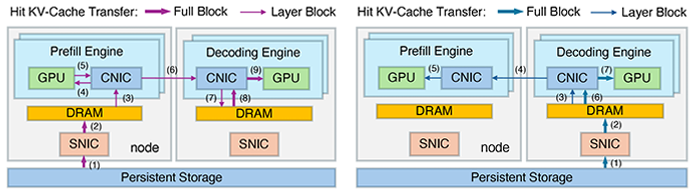
Once loaded, the data moves laterally to the prefill engines over high-speed compute networks using RDMA.
The framework incorporates real-time congestion monitoring to select optimal paths, traffic prioritization to protect latency-sensitive GPU communication, adaptive scheduling based on engine load, and layered streaming that overlaps data movement with computation to hide latency.
Long story short, DualPath is a clever inference optimization that tackles the storage I/O bottleneck in agentic LLM workloads.
Traditionally, in long, multi-turn agent sessions where KV-cache reuse is extremely high (often >95%), performance bottlenecks shift away from GPU compute and toward loading massive cached contexts from external storage back into GPU memory. In disaggregated prefill–decode setups, prefill engines saturate their storage network bandwidth while pulling KV data, whereas decode engines leave their storage links largely idle—wasting resources and capping overall throughput.
DualPath introduces a second loading path.
Instead of routing all KV-cache fetches through prefill engines, KV data can first flow through the decode engines’ underutilized storage NICs, load there, and then transfer rapidly to prefill engines via high-speed RDMA over the compute network.
A smart global scheduler continuously monitors real-time congestion, GPU utilization, and request patterns to dynamically select optimal paths. It balances workloads across engines, prioritizes latency-critical GPU traffic to avoid interference, and streams KV data in layered blocks that overlap with computation, effectively hiding I/O delays.
And the results are striking.
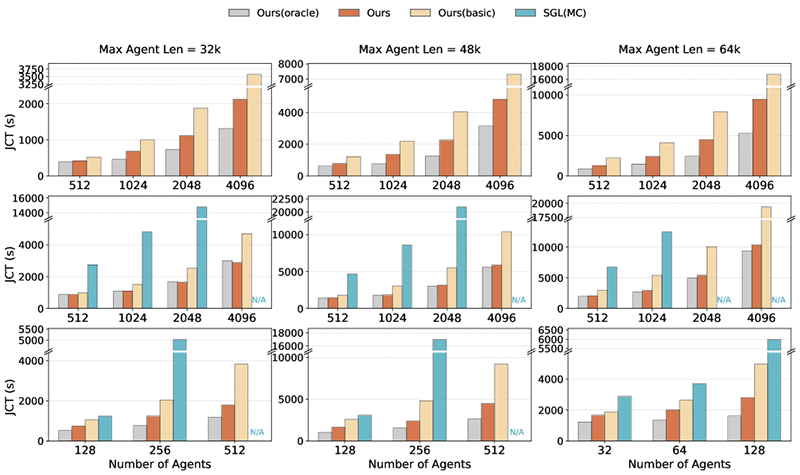
Tested on production agent workloads, including the massive DeepSeek-V3.2 660B, DualPath delivers up to 1.87× higher throughput in offline batch inference and an average 1.96× improvement in online serving capacity, all without increasing latency tails or violating service-level agreements. On smaller models and others such as Qwen2.5, gains range from 1.6× to over 2× depending on workload characteristics.
Performance scales nearly linearly across large clusters, supporting tens of thousands of concurrent agents with consistent efficiency.
This isn't flashy new reasoning or multimodality. It’s plumbing the unglamorous but essential optimization that turns theoretical capability into something deployable at scale.
By extracting nearly twice the useful work from existing GPU clusters, DualPath dramatically lowers the economic barrier to running complex, long-lived AI agents. As DeepSeek hints at an upcoming V4 release, systems like this position the company, and the broader efficiency-first movement, as a force redefining what it means to win the LLM war.
What began as a surprise shock in 2025 now looks more like sustained, structural progress—progress that may ultimately determine how AI agents move from research labs into everyday tools.


























































































































































































































































































































































































