
Artificial Intelligence is the present, and also the future of technology. With people realizing its use and potential, its development is not going to stop.
DeepMind, a subsidiary of Google that was co-founded by Mustafa Suleyman, has become one of the most prominent in the industry. The company has been conducing researches about AI since the very beginning, and since then, it has shown many compelling advances.
From making computers dream, to capable of coding, played Go and defeated a human champion, knows the concept of betrayal, and many more.
For all this time, AIs are still considered an Artificial Narrow Intelligence (ANI), in which they are only good at doing one task at time.
If researchers want AI to be able to do more than just one task at the same time in the same level as humans, it's relatively pointless to pursuit ANI. It's Artificial General Intelligence (AGI) that they should be after.
And DeepMind has been chasing that.
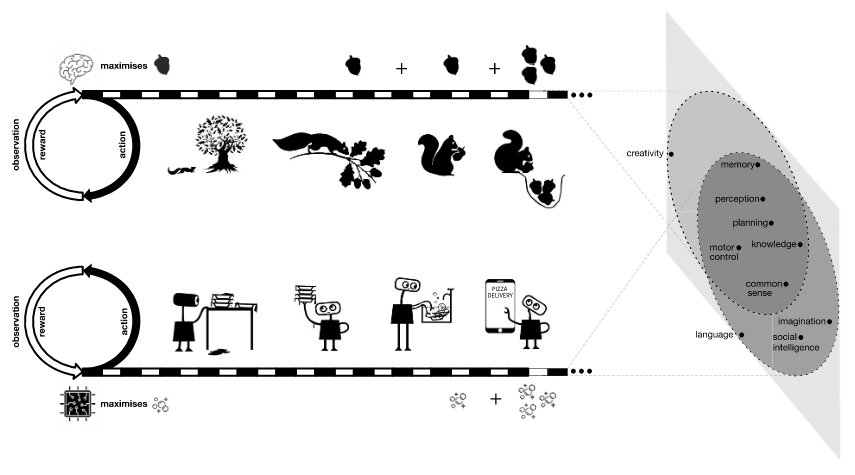
In a provocative paper on the subject: “Reward is Enough”, DeepMind researchers hypothesize that an AGI could be achieved through a single approach: reinforcement learning.
The technique trains AI by giving it feedback.
Whenever it does something wrong, it gets penalized. But when it does something right, it gets rewarded.
A positive number will tell the AI's algorithm that the action it just performed is what it is supposed to do, and that doing so will benefit it.
This particular approach was shown promise in DeepMind's MuZero. Through the project, the researchers learned that AI can be taught, and then learn and win board games, without first knowing the rules.
DeepMind called the system a "significant step forward in the pursuit of general-purpose algorithms."
This is why DeepMind suggested that "Reward is Enough", and said that reinforcement learning alone could lead to the creation of AGI.
DeepMind researchers know that in order to create AI that is smart, the AI needs to learn about the diversity of the world, and how things change or react when something is applied to it.
This hypothesis however, has been challenged by many computer scientists and researchers.
Even DeepMind's own researcher, Doina Precup, one of the paper’s co-authors.
"Ultimately, we want to test this as a hypothesis and to think of it in the context of other methods as well," said Precup, who leads DeepMind’s office at Montreal.
Precup has doubts that reward alone is enough, but believes that it could be a crucial ingredient in creating AGI.
"Because it’s learning from interaction in an incremental way, it feels very much like what biological intelligence systems do," she said. "Is it at the end of the day going to be the only technology that contributes to AGI? Well, that’s not clear at all — there’s a lot of other really interesting things that are going on."
However, Precup is optimistic as she believes the researches are already on the path to AGI. She is more concerned about how the safety of the destination than the route being taken.
Others skeptics include Raia Hadsell, DeepMind's director of robotics, who said how difficult it is to create and design an all-powerful reward to train future AGIs.
DeepMind co-founder Shane Legg suggested that reinforce learning may be a combination of learning algorithms as well.
Regardless, the people at DeepMind do believe that AGI is getting nearer. Reinforced learning is just one way. While that alone is possibly enough, there are others ways too. What's certain, the researchers believe that we're on the right path, and that is all that matters now.