
Someone (or something) who has never seen anything in life won't be able to understand anything normal people see.
To them, everything would just be a big jumble of information. Not only because the information is overwhelming, but also because the brain simply can't process anything it has no knowledge of.
Fortunately for humans, they will learn to understand what's what through experience and time, but computers couldn't do that. While computers with AI can perform image separations, but they usually require data sets with labels, as well as custom rules and a lot of learning processes before understanding anything.
In a step up from previous iterations of AI, a trio researchers .have developed an AI capable of rendering photorealistic graphical scenes with a novel viewpoint from a video.
The AI is capable of turning a video input into a bunch of points representing the geometry of the scene. The points, which form a cloud, are then fed to a neural network that renders them as computer graphics.
Below is how the AI works. The video isn’t the original input, but a rendering of it.
According to Dmitry Ulyanov, a researcher at Samsung and one of the authors on the team’s paper:
To develop this AI, which has been presented on a GitHub page, Ulyanov works with his fellow researchers Kara-Ali Aliev and Victor Lempitsky.
The method involves using point cloud with neural descriptors and camera parameters, the researchers estimate the viewpoint directions, and then rasterized the points with z-buffer using the neural descriptors concatenated with viewpoint directions as pseudo-colors. Such rasterization is then passed through the rendering network to obtain the resulting image.
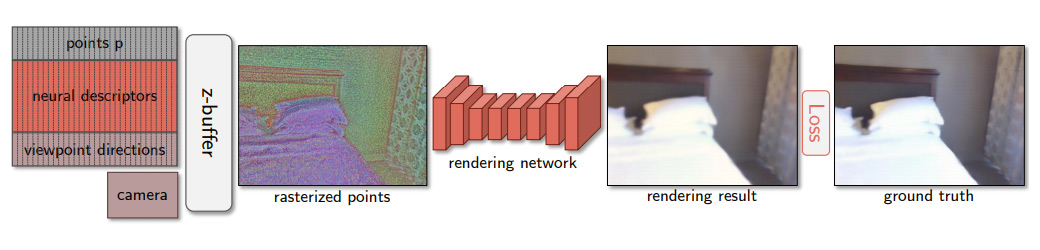
Typically, this kind of rendering is done using meshes, which overlay scenes to define the geometry of objects in space.
Those kind of methods are time-consuming, processor intensive, and require human expertise. But the researchers here created a neural point-based system which makes the AI work only a fraction of the time with a comparatively small amount of resources.
According to Ulyanov:
"Our model is fit to new scene(s) by optimizing the parameters of the rendering network and the neural descriptors by backpropagating the perceptual loss function," explained the researchers.
Here are side-by-side pictures of both rendered and nearest ground-truth:

Ulyanov said that the AI is still quite “stupid,” in that it can only attempt to reproduce a scene, meaning that it cannot alter the scene in any way.
He also also said that initially, the AI can only handle slight shifts in perspective, such as zooming or moving the “camera”, and any extreme deviation from the original viewpoint will result in artifacts.
But nevertheless, this research shows how AI can finally render photorealistic graphics from a video input in real time, with a lot less efforts than previously possible.
With this novel viewpoint including perspective-dependent features like reflections and shadows, future AI development can allow virtual reality inside of a scene from films, for example. Users can simply train a neural network and reliving it in VR from any perspective.
Ulyanov emphasizes this by saying that the researchers "actually have a standalone app where we can freely travel in the first-person mode in the scene."


























































































































































































































































































































































































