Artificial Intelligence is the future of technology, and it's becoming one of the most important topic that has been debated and argued more than many times.
As computers become smarter and able to decide things on their own, researchers are steadily seeing a shift of where humans aren't anymore the most intelligent beings.
Humans are progressing, and technologies are evolving faster as time goes on. This is because the more advanced the societies have become, the more they have the power to progress faster than those that are less advanced. In short, modern humans can accomplish much more in a year than their ancestors were capable of doing in a decade.
In their chase to create smarter AIs, researchers and computer scientists have designed and developed all kinds of complicated mechanisms and technologies to replicate vision, language, reasoning, motor skills, and other traits usually associated with intelligent life. These efforts have resulted in AI systems that can solve problems more and more efficiently.
Read: Paving The Roads To Artificial Intelligence: It's Either Us, Or Them
However, these AIs are considered Artificial Narrow Intelligence (ANI), meaning that they are only good in limited environments, and fall short of developing the kind of "general intelligence" seen in humans and animals.
ANIs are systems that have been designed to perform specific tasks instead of having general problem-solving abilities.
Some scientists believe that assembling multiple ANI modules together can create higher intelligent systems. For example, researchers can combine several ANIs together, and make them to coordinates different tasks to accomplish things like computer vision, voice processing, NLP, and motor control modules to solve complicated problems that require more complex sets of skills.
But still, they are still considered ANI. ANIs put together are still called ANI.
In a paper submitted to the peer-reviewed Artificial Intelligence journal, scientists at UK-based AI lab DeepMind said that intelligence and its associated abilities should emerge not from formulating and solving complicated problems, but by relying on the old and traditional way of teaching AI.
And that is the simple but powerful principle, called the reward maximization.
In the paper, the researchers argue that reward maximization and trial-and-error experience should be enough to help AI to develop behavior that exhibits the kind of abilities associated with intelligence.
And with that, the researchers concluded that "reinforcement learning," which is a branch of AI that is based on reward maximization, should be able to lead to the development of Artificial General Intelligence (AGI).
Another way of saying this, the researchers at DeepMind propose to recreate the simple yet effective rule that has given rise to natural intelligence.
“[We] consider an alternative hypothesis: that the generic objective of maximizing reward is enough to drive behavior that exhibits most if not all abilities that are studied in natural and artificial intelligence,” the researchers wrote.
Researchers' common method for creating AI is to try to replicate elements of intelligent behavior in computers.
In short, researchers try to replicate human abilities.
For instance, humans' knowledge of their vision system and brain functions have given the rise of different AI systems that can categorize images, locate objects in photos, define the boundaries between objects, and more. Likewise, humans' understanding of language has helped in the development of various natural language processing systems, such as question answering, text generation, and machine translation.
This is basically how nature works.
“The natural world faced by animals and humans, and presumably also the environments faced in the future by artificial agents, are inherently so complex that they require sophisticated abilities in order to succeed (for example, to survive) within those environments,” the researchers write.
“Thus, success, as measured by maximising reward, demands a variety of abilities associated with intelligence. In such environments, any behaviour that maximises reward must necessarily exhibit those abilities. In this sense, the generic objective of reward maximization contains within it many or possibly even all the goals of intelligence.”
For example, a squirrel's mean to survive is to maximize its food. In order for it to minimize hunger, it needs to rely on its various sensory and motor skills to help it locate and collect food, and protect itself from threats. But a squirrel that can only find food is bound to die of hunger when food becomes scarce. This is why it needs to also have some planning skills and memory to cache the nuts for it to consume during the winter.
The squirrel also needs social skills and knowledge to ensure other animals don’t steal its nuts, and to be able find a mater and reproduce.
Zooming out, the goal is to stay alive.
As with all complex organisms, natural selection involved different methods, based on random variations. But in all, it goes down to their fitness to survive and reproduce. Living beings that are better equipped to handle the challenges and situations in their environments should be able to survive and reproduce.
This in turn will ensure their survival as a species.
As for the rest, they will be eliminated.
And here, the researchers at DeepMind suggested that researchers can recreate those natural selections, by making AIs seek reward, and make them pursuit even larger future rewards.
“When abilities associated with intelligence arise as solutions to a singular goal of reward maximisation, this may in fact provide a deeper understanding since it explains why such an ability arises,” the researchers write. “In contrast, when each ability is understood as the solution to its own specialised goal, the why question is side-stepped in order to focus upon what that ability does.”
Finally, the researchers argue that the “most general and scalable” way to maximize reward is through agents that learn through interaction with the environment.
In the paper, the AI researchers provide some high-level examples of how “intelligence and associated abilities will implicitly arise in the service of maximising one of many possible reward signals, corresponding to the many pragmatic goals towards which natural or artificial intelligence may be directed.”
That, in what they described as “maximising a singular reward in a single, complex environment.”
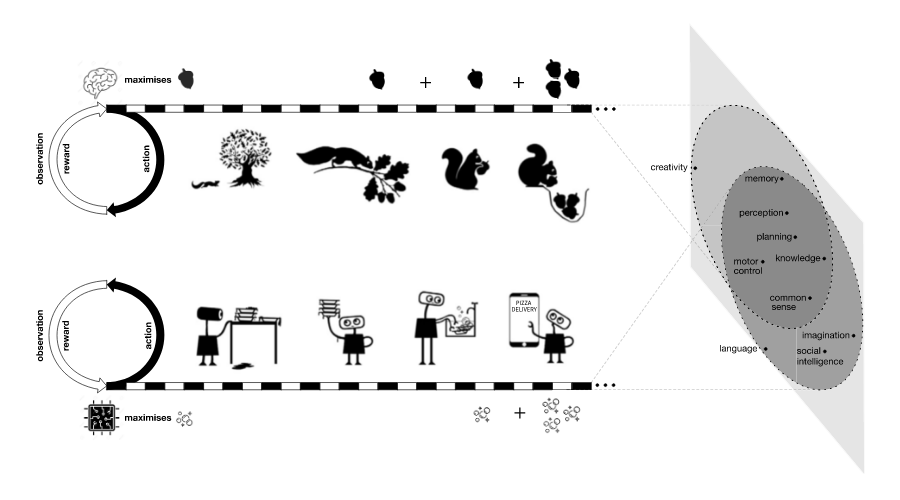
And this is where the researchers drew an analogy between natural intelligence and AGI:
The researchers suggested that reinforcement learning should be the main algorithm to replicate that reward maximization as seen in nature.
And when done successfully, this can eventually lead to AGI.
“If an agent can continually adjust its behaviour so as to improve its cumulative reward, then any abilities that are repeatedly demanded by its environment must ultimately be produced in the agent’s behaviour,” the researchers write.
They then added that in the course of maximizing for its reward, a good reinforcement learning agent could eventually learn perception, language, social intelligence and so forth.
So what does the advancement of AIs benefit humans?
To become smarter and better in what we do, humans have instincts that tell them to progress and keep on progressing. Humans want to know more, and the more they know, the more they are curious.
The human race is the most advanced species. And in terms of revolutionizing AIs, is not to only ensure humans to evolve for the better. Not just for survival, but also to revolutionize our dreams.
Further reading: Artificial General Intelligence, And How Necessary Controls Can Help Us Prepare For Their Arrival

























































































































































































































































































































































































