
Space is the dimensions of height, depth, and width. Those three variables can be represented as a 3D model, in which all things exist and move.
Humans can easily understand the definition of space, because we live inside it. Humans for example, when shown a picture of a living room, can quickly see a table in middle of a room with a tree on the outside behind the window. This ability is simple for us, enabling us to understand the world, and navigate it right from the start.
Computers vision system don't have this intuitive understanding of space, until Google's DeepMind shows that computers can indeed be taught.
DeepMind, which is Google's UK-based sister company, has developed an AI that can render entire scenes in 3D, after only observing them as flat 2D images.
To do this, the researchers trained the AI to guess how things look from angles that hasn't been seen.
Usually, in order to make computers understand 3D, something that human brain does effortlessly, researchers need to give the AI a huge amount of carefully labelled data. And still, the neural network would often have troubles in applying the lessons learned from one scene to another.
The challenge here for DeepMind, was to make the AI to understand the surrounding, without all the hard work.
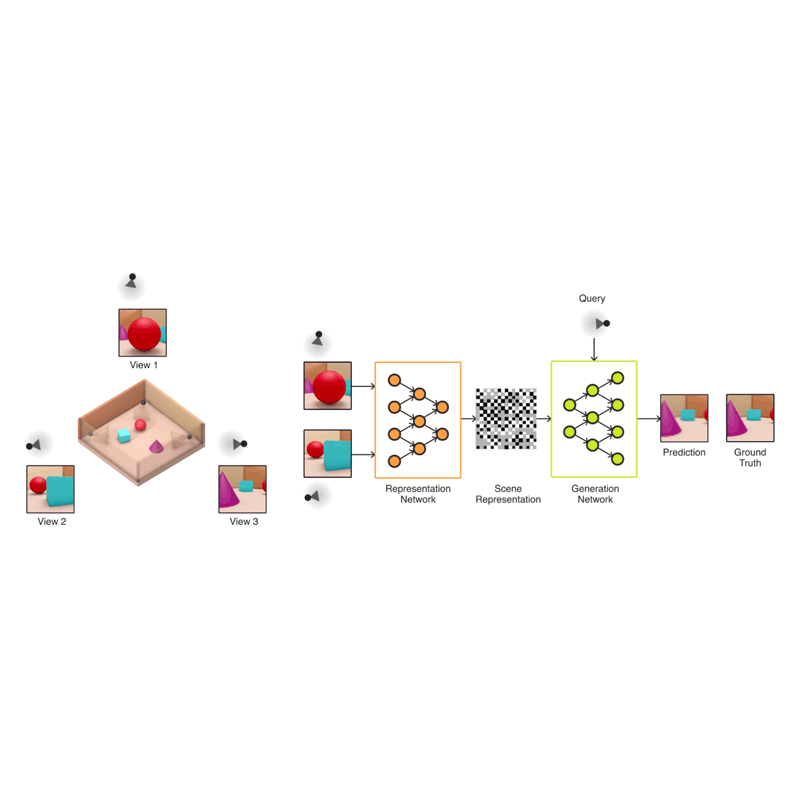
The researchers came up with a Generative Query Network (GQN), which is a neural network designed to teach AI how to imagine what a scene of objects would look like from a different perspective. It consists of two neural networks: the first learns from the images and the second generates the new perspectives.
This neural network differs from others because it is programmed to observe its surroundings, and train only on that data - not on data inputted by researchers.
As a result, GQN can learn to make sense of the world, and capable of applying the knowledge to new series without much of a problem.
And the best of all, the AI's approach does not require domain-specific engineering or time-consuming human-labelled input or previous knowledge.
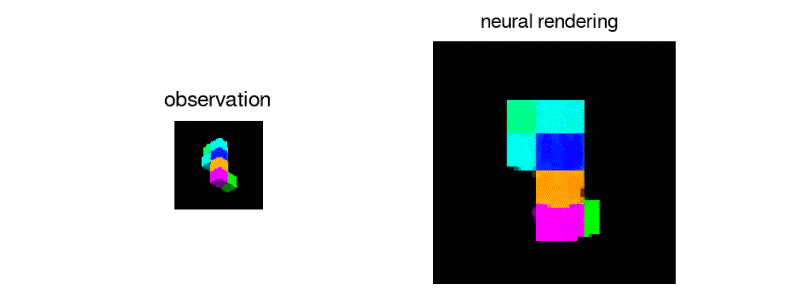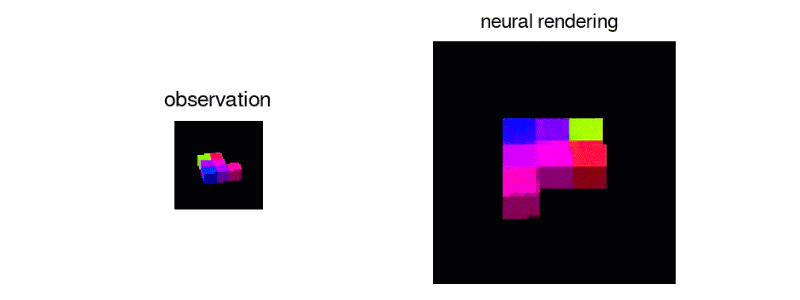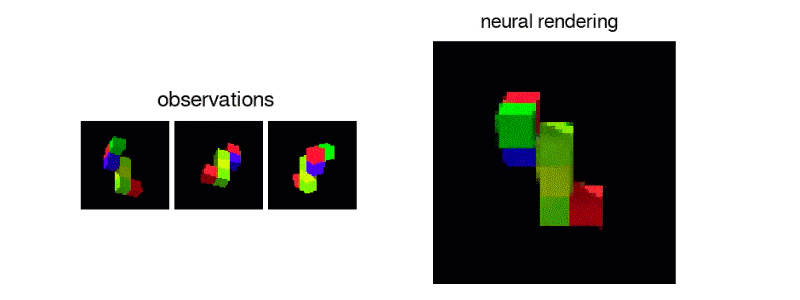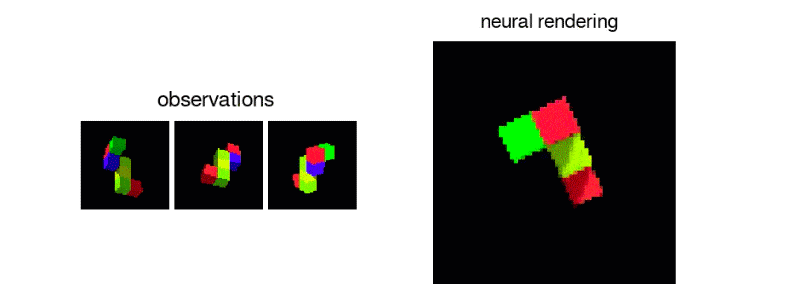
The team generated 3D virtual spaces from vectors, and then created single-frame 2D images of them for the AI to analyze.
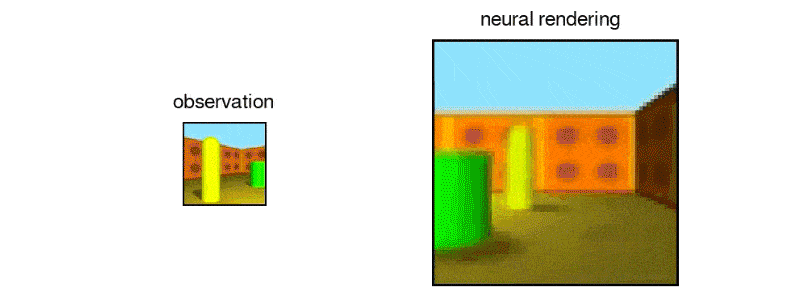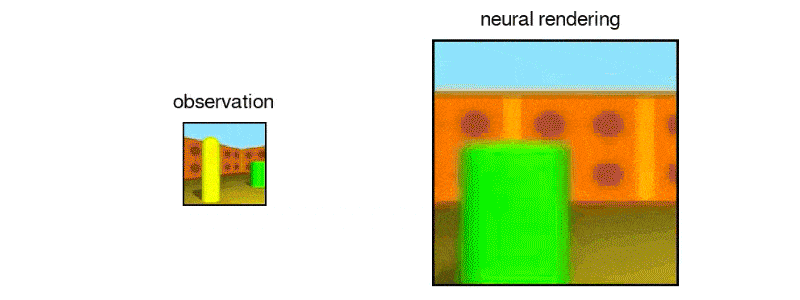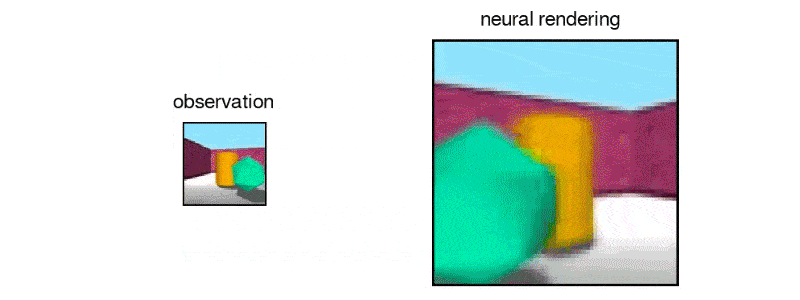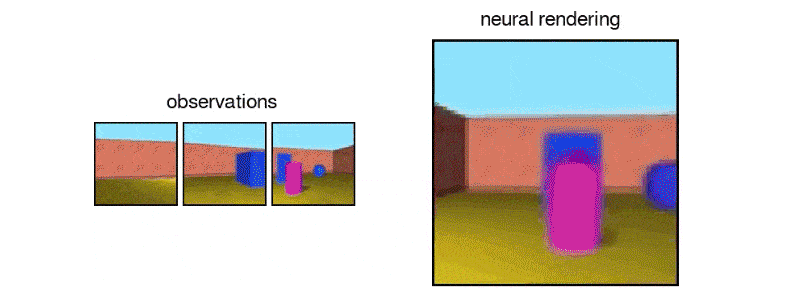
After exposing the GQN to controlled environments with millions of 2D images to teach the AI about textures, colors, and lighting of objects independently of one another and the spatial relationships between them, the researchers exposed it to randomly generated ones. By looking at only as little as three 2D images, the AI was able to imagine the scene from different angles and create a three-dimensional rendering of those images.
In DeepMind's case, the team simulated a virtual robot arm, a block-like table, and a simple maze. The AI can also understand the lines making up the cube, as well as the lightning and shadows that would change when looked at a different position.
It also was able to identify and classify the objects within its renderings, as well as make inferences based on what it can see to figure out what it can't.
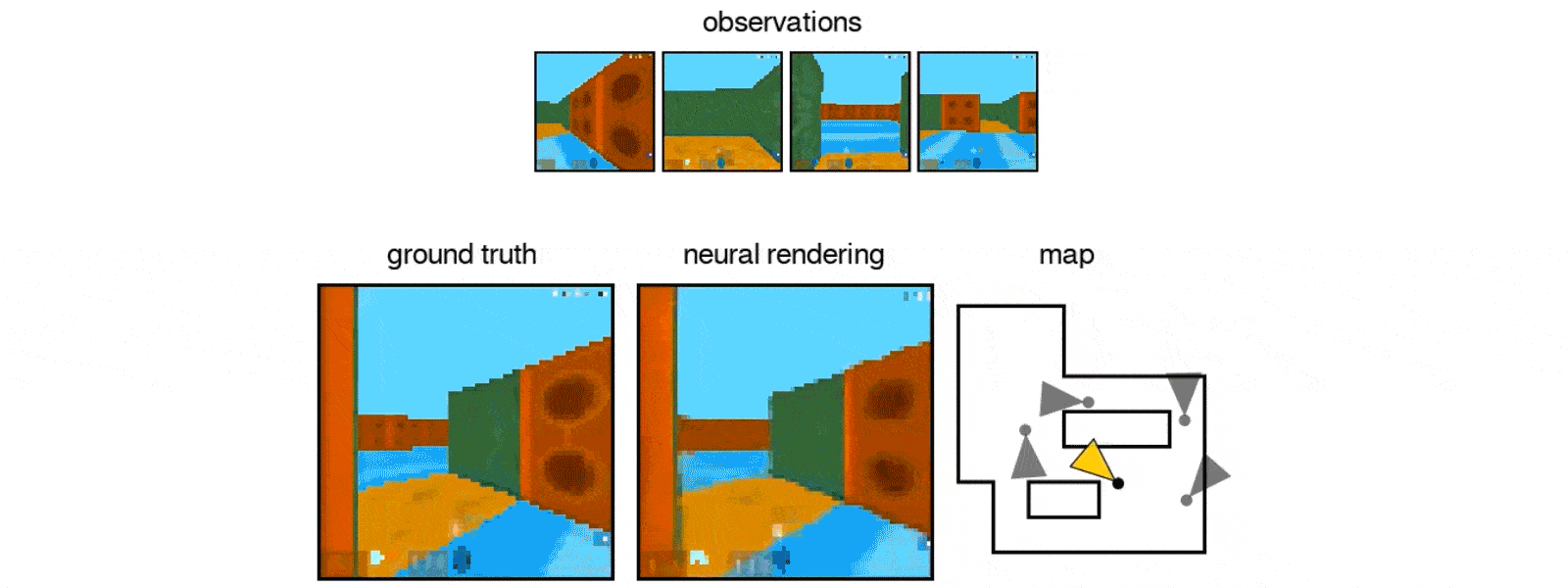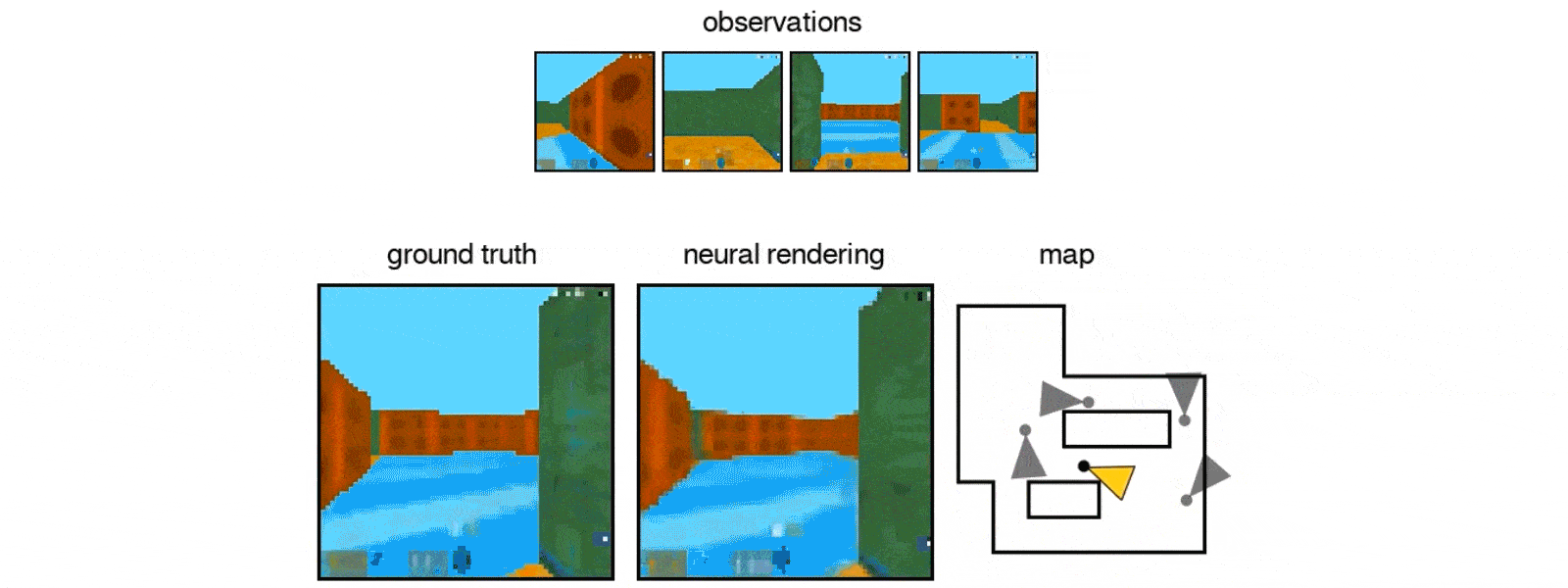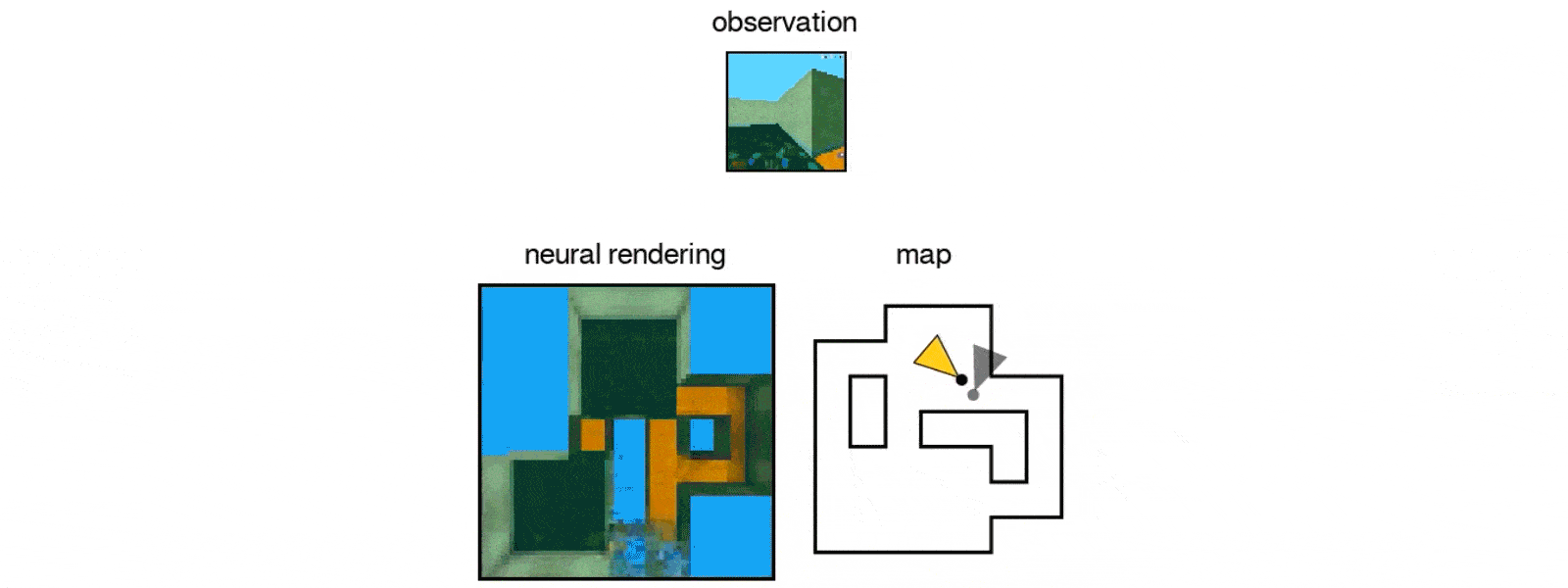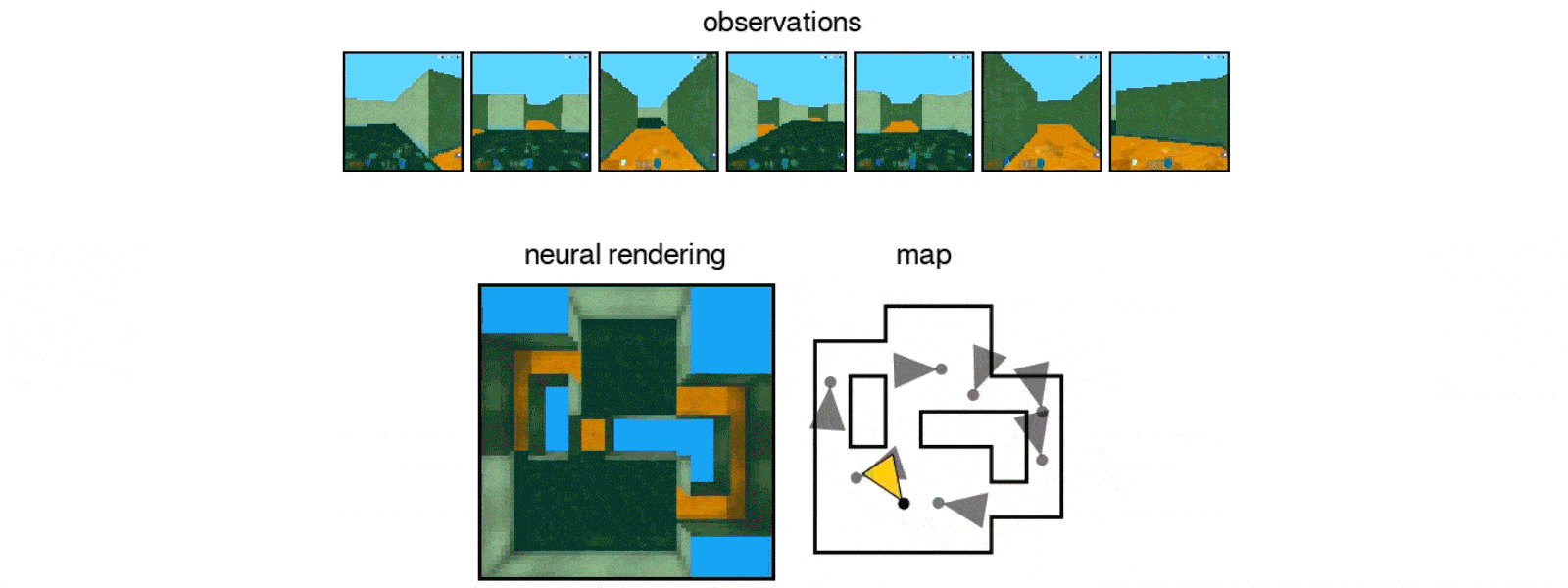
"In doing so, the GQN learns about plausible scenes and their geometrical properties, without any human labeling of the contents of scenes … The GQN learns about plausible scenes and their geometrical properties … without any human labeling of the contents of scenes."
The GQN has limitations, because it's only been tested on simple synthetic scenes containing a small number of objects.
The AI is not sophisticated enough to generate complex 3D models. But DeepMind in certain that further developments to create a more robust system with less processing power requirement and a smaller corpus, as well as frameworks that can process higher-resolution images, would make it more capable.
"While there is still much more research to be done before our approach is ready to be deployed in practice, we believe this work is a sizeable step towards fully autonomous scene understanding," the researchers wrote.
Using this method, the researchers are aiming for a "fully unsupervised scene understanding." The next step would be an AI that is easier to train, and capable of rendering realistic scenes from photographs.
Technology has no end, and what makes it great is that it overcomes dreams that once were impossible. To achieve those "dreams", we need a good imagination. And in terms of AI, we created AI in our own image.
Related: Researchers Are Able To Turn 2D Pictures Into 3D Using Machine Learning Technology