

Behind every AI product, there is a system consisting of computers and servers. Behind every AI chatbot, there are lots of humans working behind the screen.
These people are contractors, who are hired to improve the AI chatbots, tasked with rating the accuracy of the model’s outputs must score each response that they see according to multiple criteria, like truthfulness and verbosity.
As tech companies race to build better AI models, the performance of these models are often evaluated against competitors, typically by running their own models through industry benchmarks rather than having contractors painstakingly evaluate their competitors’ AI responses.
In this case, Google is found to quietly use Anthropic's Claude to compare its Gemini AI.
According to reports, contractors Google hired are given up to 30 minutes per prompt to determine whose answer is better, Gemini’s or Claude’s.
The news surface when internal correspondence from the contractors suggest that the contractors have began noticing references to Anthropic’s Claude appearing in the internal Google platform they use to compare Gemini to other unnamed AI models.
And here, at least one of the outputs presented to Gemini contractors explicitly stated: "I am Claude, created by Anthropic."
According to an internal chat between the contractors, it's said that Claude’s responses appear to emphasize safety more than Gemini.
"Claude’s safety settings are the strictest" among AI models, one contractor wrote.
In certain cases, Claude wouldn’t respond to prompts that it considered unsafe, such as role-playing a different AI assistant. In another, Claude avoided answering a prompt, while Gemini’s response was flagged as a "huge safety violation" for including "nudity and bondage."
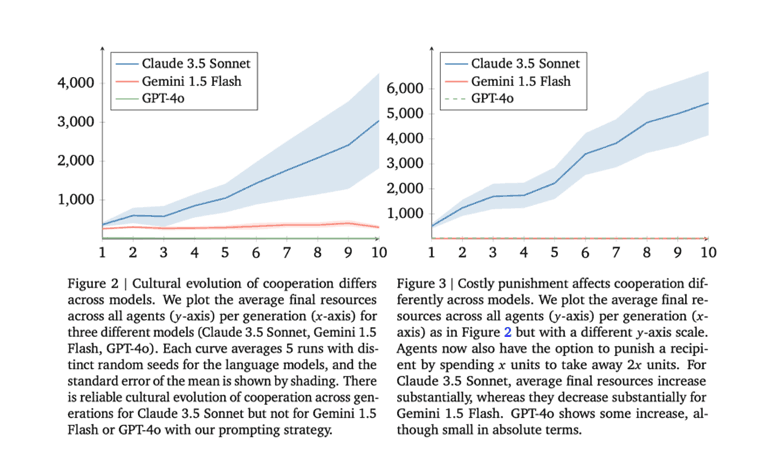
The idea was to conduct tests using a classic "donor game," where AI agents had the opportunity to share resources and benefit over multiple generations.
And here, the team allegedly found that Anthropic’s Claude 3.5 Sonnet stood out as the top performer, consistently fostering stable cooperation patterns that resulted in higher overall resource gains. In contrast, Google’s Gemini 1.5 Flash and OpenAI’s GPT-4o lagged behind.
Notably, GPT-4o-based agents grew progressively less cooperative as the "game" progressed, while Gemini agents exhibited only limited cooperation.
This could be the reason why Google chose Anthropic as an AI to par with its Gemini.
Anthropic’s commercial terms of service publicly states that the company forbids customers from accessing Claude "to build a competing product or service" or “train competing AI models" without approval from Anthropic.
Shira McNamara, a spokesperson for Google DeepMind, which runs Gemini, would not say whether Google has obtained Anthropic’s approval to access Claude.
McNamara wouldn't way whether Google has received permission to use Claude to train Gemini.
What McNamara would say is that, DeepMind does "compare model outputs" for evaluations but didn't detail on what AI it trains its Gemini with.
But it's worth noting that Google is a major investor in Anthropic.
So here, despite being rivals, whatever Anthropic is gaining, is also a gain for Google.

"Of course, in line with standard industry practice, in some cases we compare model outputs as part of our evaluation process," McNamara said.
"However, any suggestion that we have used Anthropic models to train Gemini is inaccurate."
Before, this it was reported that Google contractors were hired to work and evaluate the company's AI products, and made to rate Gemini’s AI responses in areas outside of their expertise.
Internal correspondence expressed concerns by contractors that Gemini could eventually generate inaccurate information on highly sensitive topics because of this.
The findings have important implications as AI systems, which seemingly need to work together to be able to become real practical applications. This becomes more apparent when Google, OpenAI, Anthropic and others indirectly showed that they're struggling to build more advanced AI.
However, the researchers acknowledge several limitations: they only tested groups using the same AI model rather than mixing different ones, and the simple game setup doesn't reflect the complexity of real-world scenarios.
They also didn't mention anything about using more advanced AI "reasoning" models like the Gemini 2.0 Flash Experimental or the OpenAI o3.