
The large language models (LLMs) war continues to intensify, as rivalries between tech companies know no bound.
Since the arrival of OpenAI's ChatGPT in late 2022, the AI sector has entered a period of intense competition. Major players including OpenAI, Anthropic, Google, and a growing number of Chinese laboratories have released successive generations of large language models, each aiming to advance reasoning, coding, and creative capabilities while expanding accessibility.
In this landscape, Z.ai, the organization formerly known as Zhipu AI and a spinout from Tsinghua University, has positioned itself through the GLM series of models.
The latest iteration, 'GLM-5.2,' released in mid-June 2026, recently claimed the top position on Design Arena's single-round HTML web design leaderboard in the non-agent category.
The achievement stands out because it places GLM-5.2 ahead of established leaders such as Opus 4.6, Opus 4.7 and even the newer and powerful Claude Fable 5 from Anthropic, a company already recognized for strong performance in design-oriented and coding tasks.
GLM-5.2 leads GLM-5.1 by a wide margin across various domains, including coding, tool usage, reasoning, and general knowledge. pic.twitter.com/uEzHseLizM
— Z.ai (@Zai_org) June 16, 2026
GLM-5.2 achieved this result through targeted advancements in its training and architecture.
Building on earlier versions focused on agentic engineering and long-horizon tasks, the team at Z.ai expanded reliable context handling to a full one million tokens.
This capability supports sustained performance across extended coding and creative workflows. Architectural refinements, including IndexShare for efficient reuse of sparse attention indices and KVShare to improve speculative decoding, helped reduce computational overhead while preserving quality at scale.
Training emphasized long-horizon coding-agent scenarios that encompass large-scale implementation, automated research, performance optimization, and complex debugging.
We also detail the infrastructure innovations powering our 1M context window and agentic RL. Explore the full breakdown at https://t.co/wDDG7PloPE. pic.twitter.com/Gs9fw2m87M
— Z.ai (@Zai_org) June 16, 2026
These elements appear to have translated effectively into web design generation, where the model produces coherent, interactive HTML outputs that align well with human preferences in blind evaluations.
In library usage, GLM-5.2 applied Tailwind CSS in 91% of designs and Font Awesome in 51% , patterns that contributed to higher voter approval compared with Claude Fable 5, which used Tailwind CSS in 57% of cases.
What makes this achievement particularly notable is the model's ability to generate high-quality designs.
It excels at creating clean layouts, integrating images from content delivery networks (CDNs), applying effective typography, and establishing strong visual hierarchy. It also adds subtle animations that make websites feel more dynamic and engaging.
The model integrates seamlessly with widely used libraries such as Chart.js and Three.js, further expanding its capabilities.
According to the latest results, its performance improved by approximately six percentage points compared with the previous evaluation.
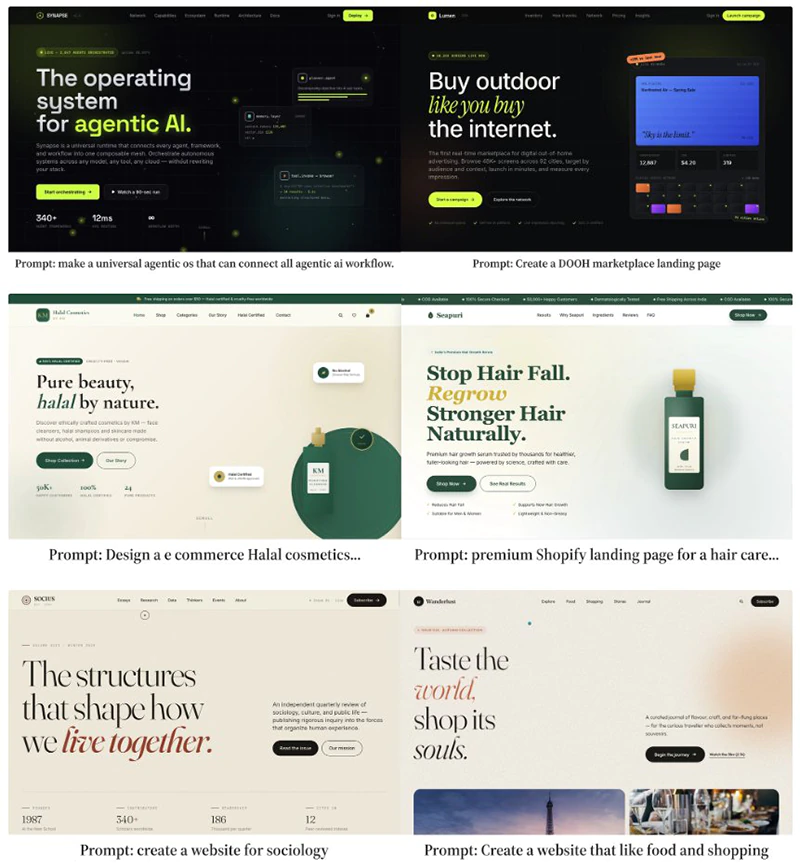
In all, GLM-5.2 improved by five positions over its predecessor GLM-5.1 and recorded an Elo score of approximately 1360 in the relevant code categories.
The broader context of GLM-5.2 includes its status as a mixture-of-experts model with roughly 744 billion total parameters and around 40 billion active per token.
It offers two reasoning-effort levels, high and max, allowing users to adjust depth versus efficiency.
On standard coding benchmarks it ranks among the strongest open-weight systems, for example reaching 81.0 on Terminal-Bench 2.1 and 62.1 on SWE-bench Pro, while placing close to frontier closed models on certain long-horizon evaluations such as FrontierSWE. API pricing remains competitive at approximately $1.40 per million input tokens and $4.40 per million output tokens.

The model weights are available under an MIT license on Hugging Face and ModelScope, enabling local deployment and fine-tuning. Users can also access it through the Z.ai chat platform and various coding agent integrations.
This combination of open licensing, extended context, architectural efficiencies, and strong benchmark results positions GLM-5.2 as a practical option for developers working on web projects, software engineering, and agentic tasks.
While Anthropic's models continue to rank among the strongest general-purpose AI systems, the Design Arena results suggest that targeted optimization for long-context, agentic workflows can deliver meaningful advantages in creative and coding tasks. GLM-5.2's performance demonstrates how specialized training focused on sustained reasoning, tool use, and large-scale implementation can translate into stronger results in specific domains such as web design generation.
Its combination of a one-million-token context window, open-weight availability, and competitive pricing reflects a broader shift in the AI industry.
As model capabilities continue to converge, factors including context length, deployment flexibility, accessibility, and domain-specific performance are becoming increasingly important alongside traditional benchmark rankings.
GLM-5.2 also delivers significant improvements in AI slide generation, long-context document processing, long-form writing, and long-context role-play. Experience these enhancements at https://t.co/gocggreDem.
— Z.ai (@Zai_org) June 16, 2026
At the same time, independent evaluations and broader real-world testing remain essential. Leaderboard performance offers valuable insight into a model's strengths, but production environments introduce additional considerations such as reliability, consistency, latency, and integration with existing workflows.
As competition between leading AI developers intensifies, releases like GLM-5.2 highlight how innovation is increasingly emerging from a wider range of organizations.