
Since we know that AI can be trained, many companies have made themselves a member in the AI race.
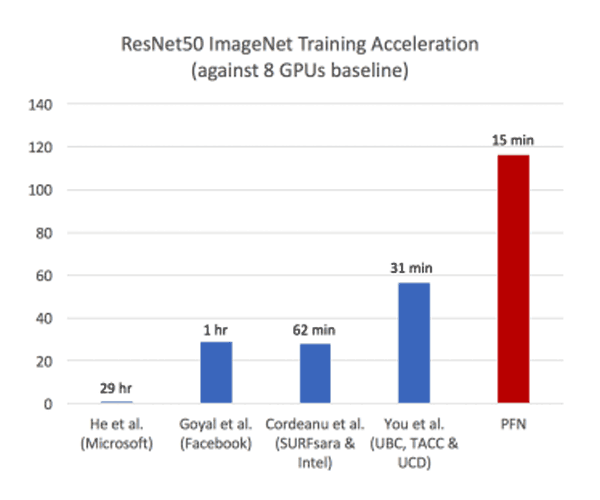
Back in summer 2017, Facebook was able to fully train an image processing AI in an hour, using 256 GPUs. Then a group from University of California, Berkeley, the University of California, Davis and the Texas Advanced Computing Center accomplished the complete training of a ResNet-50 model in 32 minutes, using 1600 Skylake processors, surpassing Facebook's record.
Then a team at Preferred Networks in Japan did it in 15 minutes using the distributed learning package ChainerMN and a large-scale parallel supercomputer comprised of 1024 Nvidia Tesla GPUs.
According to a white paper published by Takuya Akiba, Shuji Suzuki, Keisuke Fukuda, the team built on the work previously done by Facebook’s researchers.
But in order to reduce the training times, researchers chain processors together to harness their combined power, and the key difference is that the Japanese company used 32,768 minibatch, as opposed to Facebook that used a minibatch of 8,192.
So by increasing the minibatch size and using four times as many GPUs allowed the Preferred Networks to reach the record time.
The team found that the primary challenge was the optimization difficulty at the start of training.
To address this issue, they start the training with RMSprop, then gradually transition to SGD.
With Slow-Start Learning Rate Schedule, the AI can overcome the initial optimization difficulty. The team used a slightly modified learning rate schedule with a longer initial phase and lower initial learning rate. Then with Batch Normalization without Moving Averages, the team used larger minibatch sizes.
The batch normalization was to move averages of the mean and the variance that became inaccurate estimates of the actual mean and variance.
To cope with this problem, the team only considered the last minibatch, instead of the moving average, and used all-reduce communication on these statistics to obtain the average over all workers before validation.
As a result, after training on 90 epochs using 1024 GPUs, the top-1 single-crop accuracy on the validation images was 74.94 percent ± 0.09. This accuracy is comparable to that of previous results using ResNet-50. Therefore, it shows that ResNet-50 can be trained on ImageNet with a minibatch size much larger than what Facebook had, without severely degrading the accuracy.
This validated the team's claim that training of ResNet-50 can be successfully completed in 15 minutes.



























































































































































































































































































































































































